性能优化之CPU

平均负载
平均负载是指单位时间内,系统处于可运行状态和不可中断状态的平均进程 数,也就是平均活跃进程数,它和 CPU 使用率并没有直接关系。它不仅包括了正在使用 CPU的进程,还包括等待 CPU和等待 I/O的进程。
平均负载过高一般是CPU个数x1.2,如果超过这个数值那么就是高的
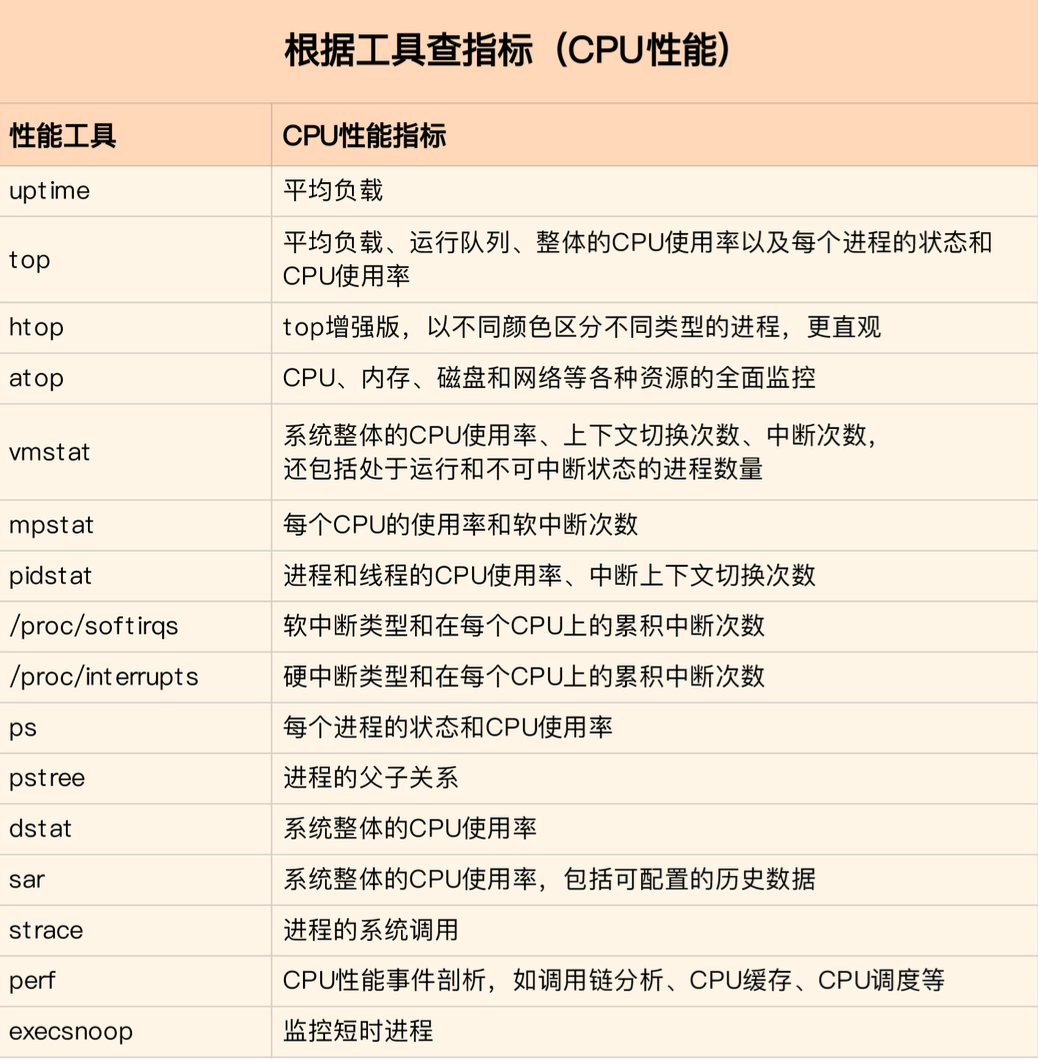
常用工具
top命令
# top命令里包含了tasks进程数、cpu用户使用率、程序使用率、平均负载、内存、缓存等。
[root@localhost ~]# top
top - 16:23:09 up 4 days, 1:10, 2 users, load average: 0.00, 0.01, 0.05
Tasks: 112 total, 1 running, 111 sleeping, 0 stopped, 0 zombie
%Cpu(s): 0.2 us, 0.0 sy, 0.0 ni, 99.8 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 3880512 total, 929572 free, 356456 used, 2594484 buff/cache
KiB Swap: 0 total, 0 free, 0 used. 3246616 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
1582 root 20 0 1342560 50840 15632 S 0.3 1.3 14:24.45 containerd
2567 root 20 0 734336 21532 6548 S 0.3 0.6 0:24.49 nerdctl
5804 root 20 0 162112 2252 1556 R 0.3 0.1 0:00.01 top
1 root 20 0 125484 3964 2616 S 0.0 0.1 0:02.19 systemd
uptime命令
# uptime命令包含了系统运行时间、用户、平局负载
[root@localhost ~]# uptime
16:24:56 up 4 days, 1:11, 2 users, load average: 0.00, 0.01, 0.05
上下文切换
Linux 是一个多任务操作系统,它支持远大于 CPU 数量的任务同时运行。当然,这些任务实际上并不是真的在同时运行,而是因为系统在很短的时间内,将 CPU 轮流分配给它们,造成多任务同时运行的错觉。而在每个任务运行前,CPU 都需要知道任务从哪里加载、又从哪里开始运行,也就是说, 需要系统事先帮它设置好 CPU 寄存器和程序计数器(Program Counter,PC)。
CPU 寄存器,是 CPU 内置的容量小、但速度极快的内存。而程序计数器,则是用来存储 CPU 正在执行的指令位置、或者即将执行的下一条指令位置。它们都是 CPU 在运行任何 任务前,必须的依赖环境,因此也被叫做 CPU 上下文。
CPU 上下文切换,就是先把前一个任务的 CPU 上下文(也就是 CPU 寄存器和程序计数器)保存起来,然后加载新任务的上下文到这些寄存器和程序计数器,最后再跳转到程序计数器所指的新位置, 运行新任务。而这些保存下来的上下文,会存储在系统内核中,并在任务重新调度执行时再次加载进来。这样就能保证任务原来的状态不受影响,让任务看起来还是连续运行。
进程上下文切换
Linux 按照特权等级,把进程的运行空间分为内核空间和用户空间。进程既可以在用户空间运行,又可以在内核空间中运行。进程在
用户空间运行时,被称为进程的用户态,而陷入内核空间的时候,被称为进程的内核态。从用户态到内核态的转变,需要通过系统调用来完成。比如,当我们查看文件内容时,就需要多次系统调用来完成:首先调用 open() 打开文件,然后调用 read() 读取文件内容, 并调用 write() 将内容写到标准输出,最后再调用 close() 关闭文件。所以,一次系统调用的过程,其实是发生了两次 CPU 上下文切换。
线程上下文切换
线程与进程最大的区别在于,线程是调度的基本单位,而进程则是资源拥有的基本单位。 说白了,所谓内核中的任务调度,实际上的调度对象是线程;而进程只是给线程提供了虚拟内存、全局变量等资源。
所以,对于线程和进程,我们可以这么理解:
- 当进程只有一个线程时,可以认为进程就等于线程。
- 当进程拥有多个线程时,这些线程会共享相同的虚拟内存和全局变量等资源。这些资源在上下文切换时是不需要修改的。另外,线程也有自己的私有数据,比如栈和寄存器等,这些在上下文切换时也是需要保存的。
这么一来,线程的上下文切换其实就可以分为两种情况:
- 第一种, 前后两个线程属于不同进程。此时,因为资源不共享,所以切换过程就跟进程上 下文切换是一样。
- 第二种,前后两个线程属于同一个进程。此时,因为虚拟内存是共享的,所以在切换时,虚拟内存这些资源就保持不动,只需要切换线程的私有数据、寄存器等不共享的数据。到这里你应该也发现了,虽然同为上下文切换,但同进程内的线程切换,要比多进程间的
切换消耗更少的资源,而这,也正是多线程代替多进程的一个优势。
中断上下文切换
为了快速响应硬件的事件,中断处理会打断进程的正常调度和执行,转而调用中断处理程序,响应设备事件。而在打断其他进程时,就需要将进程当前的状态保存下来,这样在中断结束后,进程仍然可以从原来的状态恢复运行。
总结
- CPU 上下文切换,是保证 Linux 系统正常工作的核心功能之一,一般情况下不需要我们 特别关注。
- 但过多的上下文切换,会把 CPU 时间消耗在寄存器、内核栈以及虚拟内存等数据的保存和恢复上,从而缩短进程真正运行的时间,导致系统的整体性能大幅下降。
vmstat
[root@localhost ~]# vmstat
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
1 0 0 929564 2104 2592380 0 0 0 4 8 18 0 0 100 0 0
- cs(context switch)是每秒上下文切换的次数。
- in(interrupt)则是每秒中断的次数。
- r(Running or Runnable)是就绪队列的长度,也就是正在运行和等待 CPU 的进程 数。
- b(Blocked)则是处于不可中断睡眠状态的进程数。
pidstat
# 每隔 1 秒输出 1 组数据(需要 Ctrl+C 才结束)
# -w 参数表示输出进程切换指标,而 -u 参数则表示输出 CPU 使用指标
[root@localhost ~]# pidstat -w -u 1
Linux 3.10.0-1160.el7.x86_64 (localhost.localdomain) 2023年05月26日 _x86_64_ (2 CPU)
17时03分28秒 UID PID %usr %system %guest %CPU CPU Command
17时03分28秒 UID PID cswch/s nvcswch/s Command
17时03分29秒 0 6 2.00 0.00 ksoftirqd/0
17时03分29秒 0 9 5.00 0.00 rcu_sched
17时03分29秒 0 394 20.00 0.00 xfsaild/dm-0
17时03分29秒 0 638 12.00 0.00 vmtoolsd
17时03分29秒 0 5695 1.00 0.00 kworker/0:0
17时03分29秒 0 5784 1.00 0.00 sshd
17时03分29秒 0 5826 2.00 0.00 kworker/1:2
17时03分29秒 0 5866 1.00 1.00 pidstat
- cswch ,表示每秒自愿上下文切换 (voluntary context switches)的次数,
自愿上下文切换,是指进程无法获取所需资源,导致的上下文切换。比如说, I/O、内存等系统资源不足时,就会发生自愿上下文切换。 - nvcswch ,表示每秒非自愿上下文 切换(non voluntary context switches)的次数,
非自愿上下文切换,则是指进程由于时间片已到等原因,被系统强制调度,进而发生的上下文切换。比如说,大量进程都在争抢 CPU 时,就容易发生非自愿上下文切换。
CPU 使用率
Linux 通过 /proc 虚拟文件系统,向用户空间提供了系统内部状态的信息,而 /proc/stat 提供的就是系统的 CPU 和任务统计信息。比方说,如果你只关注 CPU 的话,可以执行下面的命令:
[root@localhost ~]# cat /proc/stat |grep ^cpu
cpu 75716 16 45654 70401862 2291 0 387 0 0 0
cpu0 39814 6 26522 35194986 2262 0 131 0 0 0
cpu1 35902 9 19132 35206876 28 0 255 0 0 0
这里的输出结果是一个表格。其中,第一列表示的是 CPU 编号,如 cpu0、cpu1 ,而第一行没有编号的 cpu ,表示的是所有 CPU 的累加。其他列则表示不同场景下 CPU 的累加 节拍数,它的单位是 USER_HZ,也就是 10 ms(1/100 秒),所以这其实就是不同场景下的 CPU 时间。
下列参数是CPU使用率相关的重要指标:
- user(通常缩写为 us),代表用户态 CPU 时间。注意,它不包括下面的 nice 时间,但包括了 guest 时间。
- nice(通常缩写为 ni),代表低优先级用户态 CPU 时间,也就是进程的 nice 值被调整 为 1-19 之间时的 CPU 时间。这里注意,nice 可取值范围是 -20 到 19,数值越大,优先级反而越低。
- system(通常缩写为 sys),代表内核态 CPU 时间。
- idle(通常缩写为 id),代表空闲时间。注意,它不包括等待 I/O 的时间(iowait)。
- iowait(通常缩写为 wa),代表等待 I/O 的 CPU 时间。
- irq(通常缩写为 hi),代表处理硬中断的 CPU 时间。
- softirq(通常缩写为 si),代表处理软中断的 CPU 时间。
- steal(通常缩写为 st),代表当系统运行在虚拟机中的时候,被其他虚拟机占用的 CPU 时间。
- guest(通常缩写为 guest),代表通过虚拟化运行其他操作系统的时间,也就是运行虚 拟机的 CPU 时间。
- guest_nice(通常缩写为 gnice),代表以低优先级运行虚拟机的时间。
而我们通常所说的 CPU 使用率,就是除了空闲时间外的其他时间占总 CPU 时间的百分比,用公式来表示就是:
CPU平均使用率,就是取间隔一段时间(3秒)的两次值,作差后,再计算出这段时间内的平均CPU使用率
TOP取的CPU使用率是使用率平均时间,PS取得CPU使用率是CPU总使用时间。
top
top 显示了系统总体的 CPU 和内存使用情况,以及各个进程的资源使用情况。 ps 则只显示了每个进程的资源使用情况。
# 默认每 3 秒刷新一次
root@ubuntu:~# top
top - 07:44:22 up 6 min, 2 users, load average: 0.01, 0.09, 0.07
Tasks: 148 total, 1 running, 147 sleeping, 0 stopped, 0 zombie
%Cpu(s): 0.2 us, 0.2 sy, 0.0 ni, 99.7 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
MiB Mem : 3931.7 total, 3336.0 free, 183.4 used, 412.3 buff/cache
MiB Swap: 3931.0 total, 3931.0 free, 0.0 used. 3521.0 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
1618 root 20 0 9272 3776 3212 R 0.3 0.1 0:00.01 top
1 root 20 0 103784 12776 8448 S 0.0 0.3 0:01.44 systemd
2 root 20 0 0 0 0 S 0.0 0.0 0:00.00 kthreadd
3 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 rcu_gp
4 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 rcu_par_gp
5 root 20 0 0 0 0 I 0.0 0.0 0:00.00 kworker/0:0-memcg_kmem_cache
6 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 kworker/0:0H-kblockd
7 root 20 0 0 0 0 I 0.0 0.0 0:00.04 kworker/u4:0-events_power_efficient
8 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 mm_percpu_wq
pidstat
下面的 pidstat 命令,就间隔 1 秒展示了进程的 5 组 CPU 使用率,包括:
- 用户态 CPU 使用率 (%usr);
- 内核态 CPU 使用率(%system);
- 运行虚拟机 CPU 使用率(%guest);
- 等待 CPU 使用率(%wait);
- 以及总的 CPU 使用率(%CPU)。
- 最后的 Average 部分,还计算了 5 组数据的平均值。
root@ubuntu:~# pidstat 1 5
Linux 5.4.0-146-generic (ubuntu) 05/30/2023 _x86_64_ (2 CPU)
07:47:55 AM UID PID %usr %system %guest %wait %CPU CPU Command
07:47:56 AM 0 10 0.99 0.00 0.00 0.00 0.99 1 rcu_sched
07:47:56 AM 0 2881 0.00 0.99 0.00 0.00 0.99 1 pidstat
07:47:56 AM UID PID %usr %system %guest %wait %CPU CPU Command
07:47:57 AM 0 2881 0.00 1.00 0.00 0.00 1.00 1 pidstat
07:47:57 AM UID PID %usr %system %guest %wait %CPU CPU Command
07:47:58 AM 0 2881 0.00 1.00 0.00 0.00 1.00 1 pidstat
07:47:58 AM UID PID %usr %system %guest %wait %CPU CPU Command
07:47:59 AM 0 403 1.00 0.00 0.00 0.00 1.00 1 systemd-journal
07:47:59 AM 0 614 1.00 0.00 0.00 0.00 1.00 1 multipathd
07:47:59 AM 0 2881 0.00 1.00 0.00 0.00 1.00 1 pidstat
07:47:59 AM UID PID %usr %system %guest %wait %CPU CPU Command
07:48:00 AM 0 2881 0.00 1.00 0.00 0.00 1.00 1 pidstat
Average: UID PID %usr %system %guest %wait %CPU CPU Command
Average: 0 10 0.20 0.00 0.00 0.00 0.20 - rcu_sched
Average: 0 403 0.20 0.00 0.00 0.00 0.20 - systemd-journal
Average: 0 614 0.20 0.00 0.00 0.00 0.20 - multipathd
Average: 0 2881 0.00 1.00 0.00 0.00 1.00 - pidstat
分析 CPU 使用率
perf
通过 top、ps、pidstat 等工具可以轻松找到 CPU 使用率过高的进程。通过 perf 可以查看占用 CPU 的进程的具体函数,只有找到它才能更高效、更针对性的进行优化。
#perf top 查看了函数的 cpu 使用率
[root@localhost ~]# perf top
Samples: 690 of event 'cpu-clock', 4000 Hz, Event count (approx.): 135257776 lost: 0/0 drop: 0/0
Overhead Shared Object Symbol
10.90% [kernel] [k] vsnprintf
7.22% [kernel] [k] kallsyms_expand_symbol.constprop.1
5.80% [kernel] [k] format_decode
5.09% libc-2.17.so [.] __GI_____strtoull_l_internal
4.81% [kernel] [k] module_get_kallsym
4.15% perf [.] rb_next
3.25% [kernel] [k] string.isra.7
2.97% [kernel] [k] number.isra.2
2.83% perf [.] __dso__load_kallsyms
2.41% libc-2.17.so [.] _IO_getdelim
1.98% libc-2.17.so [.] _IO_feof
perf 可以指定进行查看它的函数使用的CPU使用率
# -g 开启调用关系分析,-p 指定 php-fpm 的进程号 21515
[root@localhost ~]# ps -ef |grep containerd
root 1582 1 0 5月22 ? 00:14:34 /usr/local/bin/containerd
[root@localhost ~]# perf top -g -p 1582
Samples: 101 of event 'cpu-clock', 4000 Hz, Event count (approx.): 19245707 lost: 0/0 drop: 0/0
Children Self Shared Object Symbol
+ 15.69% 15.69% [kernel] [k] finish_task_switch
+ 12.99% 0.00% containerd [.] 0x0000000000471ea1
+ 12.36% 0.76% [kernel] [k] ep_poll
+ 11.69% 0.00% containerd [.] 0x000000000044e03e
+ 11.69% 0.00% containerd [.] 0x000000000046fc63
+ 11.69% 0.00% containerd [.] 0x00000000004445ad
+ 11.69% 0.00% containerd [.] 0x0000000000444091
+ 11.69% 0.00% containerd [.] 0x0000000000c17a4e
+ 10.39% 0.00% [kernel] [k] system_call_fastpath
分析 CPU 使用率很高,但是却找不到 CPU 应用
当你发现系统的 CPU 使用率很高的时候,不一定能找到相对应的高 CPU 使用率的进程。此处发现下方列表进程都属于 Sleep( S )状态,排查状态属于 Running( R )的进程。发现属于 Running的进程不同在变,发现程序在不停重启。
- 进程在不停地崩溃重启,比如因为段错误、配置错误等等,这时,进程在退出后可能又被监控系统自动重启了。
- 这些进程都是短时进程,也就是在其他应用内部通过 exec 调用的外面命令。这些命令一般都只运行很短的时间就会结束,你很难用 top 这种间隔时间比较长的工具发现。
# %Cpu(s): 70.5 us 发现用户使用 CPU 很多,但是发现下方列表 %CPU 使用的却很少
root@ubuntu:~# top
top - 08:21:15 up 43 min, 3 users, load average: 0.32, 0.54, 0.77
Tasks: 180 total, 6 running, 174 sleeping, 0 stopped, 0 zombie
%Cpu(s): 70.5 us, 22.9 sy, 0.0 ni, 5.8 id, 0.0 wa, 0.0 hi, 0.8 si, 0.0 st
MiB Mem : 3931.7 total, 1231.3 free, 363.8 used, 2336.6 buff/cache
MiB Swap: 3931.0 total, 3931.0 free, 0.0 used. 3276.9 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
14698 daemon 20 0 336692 17364 9680 S 3.3 0.4 0:00.19 php-fpm
14724 daemon 20 0 336692 16320 8640 S 3.3 0.4 0:00.18 php-fpm
14704 daemon 20 0 336692 16316 8636 S 3.0 0.4 0:00.17 php-fpm
14711 daemon 20 0 336692 16320 8640 S 3.0 0.4 0:00.17 php-fpm
14531 root 20 0 720752 9660 7580 S 2.7 0.2 0:00.16 containerd-shim
14588 systemd+ 20 0 33116 3820 2440 S 2.7 0.1 0:00.16 nginx
14710 daemon 20 0 336692 16316 8636 S 2.7 0.4 0:00.17 php-fpm
14697 root 20 0 8996 5644 4980 S 1.7 0.1 0:00.10 ab
10518 root 20 0 1835080 97160 55320 S 1.3 2.4 0:12.67 dockerd
10299 root 20 0 1357196 45612 31964 S 0.3 1.1 0:06.22 containerd
14589 systemd+ 20 0 33100 3772 2440 S 0.3 0.1 0:00.01 nginx
1 root 20 0 104104 13056 8448 S 0.0 0.3 0:03.61 systemd
execsnoop
execsnoop 是一个专为短时进程设计的工具。它通过 ftrace 实时监控进程的 exec() 行为,并且输入短时进程基本信息,包括进程 PID、父进程 PID、命令行参数以及执行的结果。execsnoop 所用的 ftrace 是一种常用的动态追踪技术,一般用于分析 Linux 内核的运行 时行为。
大量不可中断进程与僵尸进程
当 iowait 升高时,进程很可能因为得不到硬件的响应,而长时间处于不可中断状态。从 ps 或者 top 命令的输出中,你可以发现它们都处于 D 状态,也就是不可中断状态 (Uninterruptible Sleep)。使用 top 查看进程状态,S 列(也就是 Status 列)表示进程的状态。从这个示例里,你可以看到 R、D、Z、S、I 等几个状态。
root@ubuntu:~# top
top - 02:29:54 up 1 day, 18:51, 2 users, load average: 0.00, 0.00, 0.00
Tasks: 161 total, 1 running, 160 sleeping, 0 stopped, 0 zombie
%Cpu(s): 0.2 us, 0.0 sy, 0.0 ni, 99.8 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
MiB Mem : 3931.7 total, 531.8 free, 291.4 used, 3108.5 buff/cache
MiB Swap: 3931.0 total, 3930.5 free, 0.5 used. 3339.3 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
10299 root 20 0 1357196 45576 31980 S 0.3 1.1 6:37.69 contain+
1 root 20 0 169620 13124 8448 S 0.0 0.3 0:07.74 systemd
2 root 20 0 0 0 0 S 0.0 0.0 0:00.02 kthreadd
3 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 rcu_gp
4 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 rcu_par+
6 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 kworker+
8 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 mm_perc+
9 root 20 0 0 0 0 S 0.0 0.0 0:00.28 ksoftir+
10 root 20 0 0 0 0 I 0.0 0.0 0:26.26 rcu_sch+
11 root rt 0 0 0 0 S 0.0 0.0 0:00.59 migrati+
12 root -51 0 0 0 0 S 0.0 0.0 0:00.00 idle_in+
14 root 20 0 0 0 0 S 0.0 0.0 0:00.00 cpuhp/0
15 root 20 0 0 0 0 S 0.0 0.0 0:00.00 cpuhp/1
16 root -51 0 0 0 0 S 0.0 0.0 0:00.00 idle_in+
17 root rt 0 0 0 0 S 0.0 0.0 0:00.68 migrati+
18 root 20 0 0 0 0 S 0.0 0.0 0:00.48 ksoftir+
20 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 kworker+
21 root 20 0 0 0 0 S 0.0 0.0 0:00.00 kdevtmp+
- R 是 Running 或 Runnable 的缩写,表示进程在 CPU 的就绪队列中,正在运行或者正 在等待运行。
- D 是 Disk Sleep 的缩写,也就是不可中断状态睡眠(Uninterruptible Sleep),一般 表示进程正在跟硬件交互,并且交互过程不允许被其他进程或中断打断。
- Z 是 Zombie 的缩写,如果你玩过“植物大战僵尸”这款游戏,应该知道它的意思。它 表示僵尸进程,也就是进程实际上已经结束了,但是父进程还没有回收它的资源(比如进程的描述符、PID 等)。
- S 是 Interruptible Sleep 的缩写,也就是可中断状态睡眠,表示进程因为等待某个事件 而被系统挂起。当进程等待的事件发生时,它会被唤醒并进入 R 状态。
- I 是 Idle 的缩写,也就是空闲状态,用在不可中断睡眠的内核线程上。前面说了,硬件 交互导致的不可中断进程用 D 表示,但对某些内核线程来说,它们有可能实际上并没有 任何负载,用 Idle 正是为了区分这种情况。要注意,D 状态的进程会导致平均负载升 高, I 状态的进程却不会。
先看不可中断状态,这其实是为了保证进程数据与硬件状态一致,并且正常情况下,不可中断状态在很短时间内就会结束。所以,短时的不可中断状态进程,我们一般可以忽略。但如果系统或硬件发生了故障,进程可能会在不可中断状态保持很久,甚至导致系统中出现大量不可中断进程。这时,你就得注意下,系统是不是出现了 I/O 等性能问题。
再看僵尸进程,这是多进程应用很容易碰到的问题。正常情况下,当一个进程创建了子进程后,它应该通过系统调用 wait() 或者 waitpid() 等待子进程结束,回收子进程的资源;而子进程在结束时,会向它的父进程发送 SIGCHLD 信号,所以,父进程还可以注册 SIGCHLD 信号的处理函数,异步回收资源。如果父进程没这么做,或是子进程执行太快,父进程还没来得及处理子进程状态,子进程就已经提前退出,那这时的子进程就会变成僵尸进程。换句话说,父亲应该一直对儿子负责,善始善终,如果不作为或者跟不上,都会导致“问题少年”的出现。通常,僵尸进程持续的时间都比较短,在父进程回收它的资源后就会消亡;或者在父进程 退出后,由 init 进程回收后也会消亡。一旦父进程没有处理子进程的终止,还一直保持运行状态,那么子进程就会一直处于僵尸 状态。大量的僵尸进程会用尽 PID 进程号,导致新进程不能创建,所以这种情况一定要避 免。
处理思路:大量 I/O Wait 可以通过 top 查看到状态是 D 的进程,通过 pidstat 查看进行占用的 I/O,僵尸进程 通过 top 查看状态是是 Z 的进程,通过 pstree 查看,找到父进程重启父进程。
软中断
proc 文件系统,它是一种内核空间和用户空间进行通信的机制,可以用来查看内核的数据结构,或者用来动态修改内核的配置。其中:
- /proc/softirqs 提供了软中断的运行情况;
- /proc/interrupts 提供了硬中断的运行情况。
查看 /proc/softirqs 文件的内容,你就可以看到各种类型软中断在不同 CPU 上的累积运行次数:
root@ubuntu:~# cat /proc/softirqs
CPU0 CPU1
HI: 0 0
TIMER: 2644715 5501772
NET_TX: 15 30782
NET_RX: 675786 847450
BLOCK: 175276 306011
IRQ_POLL: 0 0
TASKLET: 13022 8796
SCHED: 2508465 5388548
HRTIMER: 9868 28600
RCU: 1966937 3065234
- 第一,要注意软中断的类型,也就是这个界面中第一列的内容。从第一列你可以看到,软 中断包括了 10 个类别,分别对应不同的工作类型。比如 NET_RX 表示网络接收中断,而 NET_TX 表示网络发送中断。
- 第二,要注意同一种软中断在不同 CPU 上的分布情况,也就是同一行的内容。正常情况下,同一种中断在不同 CPU 上的累积次数应该差不多。比如这个界面中,NET_RX 在 CPU0 和 CPU1 上的中断次数基本是同一个数量级,相差不大。不过你可能发现,TASKLET 在不同 CPU 上的分布并不均匀。TASKLET 是最常用的软中断实现机制,每个 TASKLET 只运行一次就会结束 ,并且只在调用它的函数所在的 CPU 上 运行。因此,使用 TASKLET 特别简便,当然也会存在一些问题,比如说由于只在一个 CPU 上运行导致的调度不均衡,再比如因为不能在多个 CPU 上并行运行带来了性能限制。
软中断 CPU 使用率(softirq)升高是一种很常见的性能问题。虽然软中断的类型很多, 但实际生产中,我们遇到的性能瓶颈大多是网络收发类型的软中断,特别是网络接收的软中断。在碰到这类问题时,你可以借用 sar、tcpdump 等工具,做进一步分析。
迅速分析CPU性能瓶颈
描述CPU性能指标:
CPU 使用率描述了非空闲时间占总 CPU 时间的百分比,根据 CPU 上运行任务的不同,又被分为用户 CPU、系统 CPU、等待 I/O CPU、软中断和硬中断等。
用户 CPU 使用率,包括用户态 CPU 使用率(user)和低优先级用户态 CPU 使用率 (nice),表示 CPU 在用户态运行的时间百分比。用户 CPU 使用率高,通常说明有应 用程序比较繁忙。系统 CPU 使用率,表示 CPU 在内核态运行的时间百分比(不包括中断)。系统 CPU 使用率高,说明内核比较繁忙。等待 I/O 的 CPU 使用率,通常也称为 iowait,表示等待 I/O 的时间百分比。iowait 高,通常说明系统与硬件设备的 I/O 交互时间比较长。软中断和硬中断的 CPU 使用率,分别表示内核调用软中断处理程序、硬中断处理程序的时间百分比。它们的使用率高,通常说明系统发生了大量的中断。除了上面这些,还有在虚拟化环境中会用到的窃取 CPU 使用率(steal)和客户 CPU 使 用率(guest),分别表示被其他虚拟机占用的 CPU 时间百分比,和运行客户虚拟机的 CPU 时间百分比。
平均负载(Load Average),也就是系统的平均活跃进程数。它反应了系统的整体负载情况,主要包括三个数值,分别指过去 1 分钟、过去 5 分 钟和过去 15 分钟的平均负载。理想情况下,平均负载等于逻辑 CPU 个数,这表示每个 CPU 都恰好被充分利用。如果平均负载大于逻辑 CPU 个数,就表示负载比较重了。
进程上下文切换,包括无法获取资源而导致的自愿上下文切换;被系统强制调度导致的非自愿上下文切换。
上下文切换,本身是保证 Linux 正常运行的一项核心功能。但过多的上下文切换,会将原本运行进程的 CPU 时间,消耗在寄存器、内核栈以及虚拟内存等数据的保存和恢复上,缩短进程真正运行的时间,成为性能瓶颈。
CPU 缓存的命中率。由于 CPU 发展的速度远快于内存的发展,CPU 的处理速度就比内存的访问速度快得多。这样,CPU 在访问内存的时候,免不了要等待内存的响应。为了协调这两者巨大的性能差距,CPU 缓存(通常是多级缓存)就出现了。
性能工具