
论 Pod 调度
在 kubernetes 中,无论是 Deployment、Statefulset 等多种控制器,它最终都是创建 Pod,在 Pod 创建是需要被调度到 Kubernetes 集群的 Node 节点中的,此处分析影响 Pod 调度到节点的几种因素。
定向调度
- 修改 Pod 编排模板中的 spec.nodeName 为指定 node
- nodeSelector 选择标签
亲和性调度
- Pod 亲和性与反亲和性
- Node 亲和性
污点与容忍
- 污点
- 容忍
调度器打分
- 调度器打分
自研发调度功能
- 自研的调度器或者控制器
Pod 中的 nodeName
在查看 Pod 发现 web-0 在 kube02 节点,通过查看spec内容发现nodeName为kube02,我们通过尝试修改指定 nodeName看看 Pod 会不会调度到指定节点。
[root@kube01 pki]# kubectl get pod -o wide -l app=nginx
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
web-0 1/1 Running 0 3d6h 172.30.1.198 kube02 <none> <none>
web-1 1/1 Running 0 3d5h 172.30.1.205 kube02 <none> <none>
[root@kube01 pki]# kubectl get pod web-0 -o yaml
...
spec:
containers:
- image: nginx:1.7.9
imagePullPolicy: IfNotPresent
name: nginx
ports:
- containerPort: 80
name: web
protocol: TCP
resources: {}
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
volumeMounts:
- mountPath: /usr/share/nginx/html
name: www
- mountPath: /var/run/secrets/kubernetes.io/serviceaccount
name: kube-api-access-b2m4j
readOnly: true
dnsPolicy: ClusterFirst
enableServiceLinks: true
hostname: web-0
nodeName: kube02
preemptionPolicy: PreemptLowerPriority
priority: 0
restartPolicy: Always
schedulerName: default-scheduler
securityContext: {}
serviceAccount: default
serviceAccountName: default
...
创建 Pod 的 Yaml 文件,实现创建一个在 kube01 节点的 Pod,发现了只要在spec下配置nodeName就可以实现,由此可以知道 Pod 在哪个节点有nodeName决定,这是因为在 Kubernetes 调度器中,SchedulerWatchPod 的时候,发现 Pod 已经存在 nodeName 就会跳过调度过程
# cat nodeName-Pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: test-nodename
labels:
app: jixingxing
spec:
containers:
- name: nodename
image: busybox
command: ["sleep", "36000"]
nodeName: kube01
[root@kube01 ~]# kubectl apply -f stu/job/nodeName-Job.yaml
pod/test-nodename created
[root@kube01 ~]# kubectl get pod -o wide -l app=jixingxing
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
test-nodename 0/1 ContainerCreating 0 9s <none> kube01 <none> <none>
nodeSelector 选择器
通过查看 node 节点标签,观察到 kube02 有status=health标签,创建 Pod 使用 nodeSelector 选择 kube02 标签
[root@kube01 ~]# kubectl get nodes --show-labels
NAME STATUS ROLES AGE VERSION LABELS
kube01 Ready control-plane,master 133d v1.23.6 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=kube01,kubernetes.io/os=linux,node-role.kubernetes.io/control-plane=,node-role.kubernetes.io/master=,node.kubernetes.io/exclude-from-external-load-balancers=
kube02 Ready <none> 133d v1.23.6 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=kube02,kubernetes.io/os=linux,status=health
通过创建了一个 Pod 选择了status=health的标签,发现它被调度到 kube02 节点,如果node标签没有的话就会pending,这是因为 Scheduler 调度器中的label-selector功能,它会判断有没有节点标签,跳过打分过程。
# cat nodeSelector-Pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: test-nodeselector
labels:
app: jixingxing
spec:
containers:
- name: nodeselector
image: busybox
command: ["sleep", "36000"]
nodeSelector:
status: health
# kubectl apply -f nodeName-Job.yaml
pod/test-nodeselector created
# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
test-nodeselector 0/1 ContainerCreating 0 4s <none> kube02 <none> <none>
此时突发奇想nodeName与nodeSelector同时存在但是相反会怎么样?配置了nodeName为 kube01,nodeSelector为 kube02,发现 Pod 已经调度到 kube01 节点,但是却启动不了,报亲和性失败问题。由此判断两中选择类型应该都是强制约束的。
# cat nodeSelector-Pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: test-nodeselector
labels:
app: jixingxing
spec:
containers:
- name: nodename
image: busybox
command: ["sleep", "36000"]
nodeName: kube01
nodeSelector:
status: health
# kubectl apply -f nodeSelector-Pod.yaml
pod/test-nodeselector created
# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
test-nodeselector 0/1 NodeAffinity 0 8s <none> kube01 <none> <none>
Pod 亲和性与反亲和性
亲和性
它基于运行在 node 上的 pod 标签来限制 pod 调度在哪个节点上,而不是节点的标签
Pod 亲和性分为硬策略与软策略两种,硬策略强制调用到匹配节点,如果没有对应节点则 Pod 不会被调度;软策略就是优先匹配有标签的节点,如果没有的话会继续调度 Pod
# cat pod-affinity
apiVersion: v1
kind: Pod
metadata:
name: with-pod-affinity
spec:
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- jixingxing
topologyKey: kubernetes.io/hostname
containers:
- name: busybox
image: busybox
command: ['sleep', '3600']
在 yaml 文件中,affinity为亲和性,podAffinity为 Pod 亲和性,requiredDuringSchedulingIgnoredDuringExecution为硬策略没有达到亲和性要求则不调度,labelSelector为标签选择器,operator有四种表达式In NotIn Exists DoesNotExist,topologyKey为寻找 node 节点(意思在 node 标签为 kubernetes.io/hostname 的节点上寻找 pod 标签,这里是硬策略没有的话就不调度)
执行后查看 Pod 所属节点,发现已经被调度到 kube01 节点
# kubectl get pod --show-labels -l app=jixingxing -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES LABELS
test-nodename 1/1 Running 2 (71m ago) 21h 172.30.0.25 kube01 <none> <none> app=jixingxing
test-nodeselector 1/1 Running 0 3h32m 172.30.0.89 kube01 <none> <none> app=jixingxing
[root@kube01 ~]# kubectl get nodes --show-labels
NAME STATUS ROLES AGE VERSION LABELS
kube01 Ready control-plane,master 134d v1.23.6 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=kube01,kubernetes.io/os=linux,node-role.kubernetes.io/control-plane=,node-role.kubernetes.io/master=,node.kubernetes.io/exclude-from-external-load-balancers=
kube02 Ready <none> 134d v1.23.6 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=kube02,kubernetes.io/os=linux,status=health
[root@kube01 ~]# kubectl get pod --show-labels -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES LABELS
with-pod-affinity 0/1 ContainerCreating 0 7s <none> kube01 <none> <none> <none>
设置一个没有的标签查看效果,发现 Pod Pending 中
apiVersion: v1
kind: Pod
metadata:
name: with-pod-affinity
spec:
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- jixingxing001
topologyKey: kubernetes.io/hostname
containers:
- name: busybox
image: busybox
command: ['sleep', '3600']
[root@kube01 ~]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
with-pod-affinity 0/1 Pending 0 9s <none> <none> <none> <none>
[root@kube01 ~]# kubectl describe pod with-pod-affinity
Name: with-pod-affinity
Namespace: default
Priority: 0
Node: <none>
Labels: <none>
Annotations: <none>
Status: Pending
IP:
IPs: <none>
Containers:
busybox:
Image: busybox
Port: <none>
Host Port: <none>
Command:
sleep
3600
Environment: <none>
Mounts:
/var/run/secrets/kubernetes.io/serviceaccount from kube-api-access-zw6p7 (ro)
Conditions:
Type Status
PodScheduled False
Volumes:
kube-api-access-zw6p7:
Type: Projected (a volume that contains injected data from multiple sources)
TokenExpirationSeconds: 3607
ConfigMapName: kube-root-ca.crt
ConfigMapOptional: <nil>
DownwardAPI: true
QoS Class: BestEffort
Node-Selectors: <none>
Tolerations: node.kubernetes.io/not-ready:NoExecute op=Exists for 300s
node.kubernetes.io/unreachable:NoExecute op=Exists for 300s
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedScheduling 28s default-scheduler 0/2 nodes are available: 2 node(s) didn't match pod affinity rules.
再次创建一个软策略找一个没有的标签,需要注意的是硬限制跟软限制模板不一样,preferredDuringSchedulingIgnoredDuringExecution为软限制,weight为匹配相关联的权重,设置为 100 就是严格按照匹配规则打分。
# cat pod-affinity
apiVersion: v1
kind: Pod
metadata:
name: with-pod-affinity
spec:
affinity:
podAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
podAffinityTerm:
labelSelector:
matchExpressions:
- key: app
operator: In
values:
- jixingxing001
topologyKey: kubernetes.io/hostname
containers:
- name: busybox
image: busybox
command: ['sleep', '3600']
查看结果效果软限制匹配了标签,没有它也会创建
[root@kube01 ~]# kubectl apply -f pod-affinity
pod/with-pod-affinity created
[root@kube01 ~]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
with-pod-affinity 0/1 ContainerCreating 0 6s <none> kube01 <none> <none>
反亲和性
Pod 亲和性就是根据规则匹配 Pod 标签,如果有就往它靠近,反亲和就是如果有就不往它靠近
# cat pod-affinity
apiVersion: v1
kind: Pod
metadata:
name: with-pod-affinity
spec:
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- jixingxing
topologyKey: kubernetes.io/hostname
containers:
- name: busybox
image: busybox
command: ['sleep', '3600']
# cat pod-affinity
apiVersion: v1
kind: Pod
metadata:
name: with-pod-affinity
spec:
affinity:
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
podAffinityTerm:
labelSelector:
matchExpressions:
- key: app
operator: In
values:
- jixingxing
topologyKey: kubernetes.io/hostname
containers:
- name: busybox
image: busybox
command: ['sleep', '3600']
查看执行结果
[root@kube01 ~]# kubectl apply -f pod-affinity
pod/with-pod-affinity created
[root@kube01 ~]# kubectl get pod -o wide --show-labels
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES LABELS
test-nodename 1/1 Running 2 (96m ago) 21h 172.30.0.25 kube01 <none> <none> app=jixingxing
test-nodeselector 1/1 Running 0 3h58m 172.30.0.89 kube01 <none> <none> app=jixingxing
with-pod-affinity 1/1 Running 0 115s 172.30.0.80 kube02 <none> <none> <none>
Node 亲和性
Node 只有亲和性没有反亲和性,可以通过 explain 查看
[root@kube01 ~]# kubectl explain pod.spec.affinity
KIND: Pod
VERSION: v1
RESOURCE: affinity <Object>
DESCRIPTION:
If specified, the pod's scheduling constraints
Affinity is a group of affinity scheduling rules.
FIELDS:
nodeAffinity <Object>
Describes node affinity scheduling rules for the pod.
podAffinity <Object>
Describes pod affinity scheduling rules (e.g. co-locate this pod in the
same node, zone, etc. as some other pod(s)).
podAntiAffinity <Object>
Describes pod anti-affinity scheduling rules (e.g. avoid putting this pod
in the same node, zone, etc. as some other pod(s)).
硬策略亲和
[root@kube01 ~]# cat node-affinity
apiVersion: v1
kind: Pod
metadata:
name: with-node-affinity
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/hostname
operator: In
values:
- kube01
containers:
- name: busybox
image: busybox
command: ['sleep', '3600']
软策略亲和
apiVersion: v1
kind: Pod
metadata:
name: with-node-affinity
spec:
affinity:
nodeAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
preference:
matchExpressions:
- key: kubernetes.io/hostname
operator: In
values:
- kube01
containers:
- name: busybox
image: busybox
command: ['sleep', '3600']
执行发现亲和性成功
[root@kube01 ~]# kubectl get node
NAME STATUS ROLES AGE VERSION
kube01 Ready control-plane,master 134d v1.23.6
kube02 Ready <none> 134d v1.23.6
[root@kube01 ~]# kubectl get pod -o wide --show-labels
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES LABELS
with-node-affinity 0/1 ContainerCreating 0 2s <none> kube01 <none> <none> <none>
污点与容忍
如果一个节点标记为 Taints ,除非 Pod 被标识为可以容忍污点节点,否则该 Taints 节点不会被调度 Pod,在实际使用 Kubernetes 集群环境中,一般 Master 节点因为存在 API Server 等核心组件,所以会给 Master 节点打上污点让它不允许被调度。
查看 Node 节点污点,发现污点为NoSchedule不可调度,污点状态有多种分别为:
- NoSchedule:不可调度
- PreferNoSchedule:尽量不调度
- NoExecute:该节点内正在运行的 pod 没有对应 Tolerate 设置,会直接被逐出(前两种已经存在的不会被驱逐这个会)
[root@kube01 ~]# kubectl describe node kube01
Name: kube01
Roles: control-plane,master
Labels: beta.kubernetes.io/arch=amd64
beta.kubernetes.io/os=linux
kubernetes.io/arch=amd64
kubernetes.io/hostname=kube01
kubernetes.io/os=linux
node-role.kubernetes.io/control-plane=
node-role.kubernetes.io/master=
node.kubernetes.io/exclude-from-external-load-balancers=
Annotations: flannel.alpha.coreos.com/backend-data: {"VNI":1,"VtepMAC":"12:81:9d:ec:18:fe"}
flannel.alpha.coreos.com/backend-type: vxlan
flannel.alpha.coreos.com/kube-subnet-manager: true
flannel.alpha.coreos.com/public-ip: 192.168.17.42
kubeadm.alpha.kubernetes.io/cri-socket: /var/run/dockershim.sock
node.alpha.kubernetes.io/ttl: 0
volumes.kubernetes.io/controller-managed-attach-detach: true
CreationTimestamp: Thu, 09 Mar 2023 11:24:38 +0800
Taints: node-role.kubernetes.io/master:NoSchedule
只有在 Pod 中设置容忍在可以使用该节点,需要注意的是容忍不代表调度,容忍只是调度时多一个节点选择,污点容忍一般在 DaemonSet 时使用
# cat tolerations.yaml
apiVersion: v1
kind: Pod
metadata:
name: taint
spec:
containers:
- name: busybox
image: busybox
command: ['sleep', '3600']
tolerations:
- key: "node-role.kubernetes.io/master"
operator: "Exists"
effect: "NoSchedule"
调度器打分
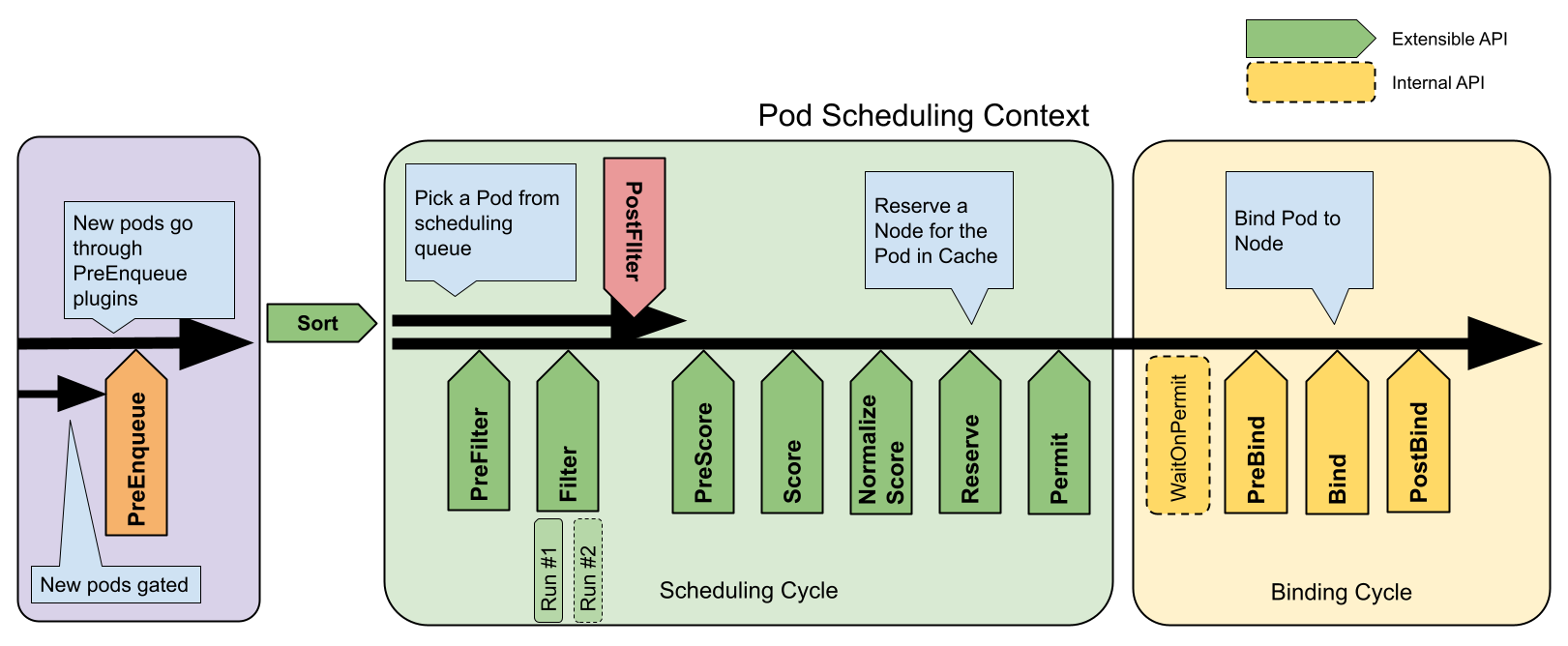
调度 Pod 可以分为以下几个阶段:
- 预入队列:将 Pod 被添加到内部活动队列之前被调用,在此队列中 Pod 被标记为准备好进行调度
- 排队:用于对调度队列中的 Pod 进行排序。
- 过滤:过滤掉不满足条件的节点
- 打分:对通过的节点按照优先级排序
- 保留资源:因为是 Pod 的创建是异步的,所以需要在找到最合适的机器后先进行资源的保留
- 批准、拒绝、等待:调度完成后对于发送 Pod 的信息进行批准、拒绝、等待
- 绑定:最后从中选择优先级最高的节点,如果中间任何一步骤有错误,就直接返回错误
预入队列
PreEnqueue
这些插件在将 Pod 被添加到内部活动队列之前被调用,在此队列中 Pod 被标记为准备好进行调度。
只有当所有 PreEnqueue 插件返回Success时,Pod 才允许进入活动队列。 否则,它将被放置在内部无法调度的 Pod 列表中,并且不会获得Unschedulable状态。
排队
Sort
Sort 用于对调度队列中的 Pod 进行排序。 队列排序插件本质上提供 less(Pod1, Pod2) 函数。 一次只能启动一个队列插件。
过滤
PreFilter
这些插件用于预处理 Pod 的相关信息,或者检查集群或 Pod 必须满足的某些条件。如果 PreFilter 插件返回错误,则调度周期将终止。
Filter
这些插件用于过滤出不能运行该 Pod 的节点。对于每个节点,调度器将按照其配置顺序调用这些过滤插件。如果任何过滤插件将节点标记为不可行,则不会为该节点调用剩下的过滤插件。节点可以被同时进行评估。
PostFilter
这些插件在 Filter 阶段后调用,但仅在该 Pod 没有可行的节点时调用。 插件按其配置的顺序调用。如果任何 PostFilter 插件标记节点为“Schedulable”, 则其余的插件不会调用。典型的 PostFilter 实现是抢占,试图通过抢占其他 Pod 的资源使该 Pod 可以调度。
打分
PreScore
这些插件用于执行 “前置评分(pre-scoring)” 工作,即生成一个可共享状态供 Score 插件使用。 如果 PreScore 插件返回错误,则调度周期将终止。
Score
这些插件用于对通过过滤阶段的节点进行排序。调度器将为每个节点调用每个评分插件。 将有一个定义明确的整数范围,代表最小和最大分数。 在标准化评分阶段之后,调度器将根据配置的插件权重合并所有插件的节点分数。
NormalizeScore
这些插件用于在调度器计算 Node 排名之前修改分数。 在此扩展点注册的插件被调用时会使用同一插件的 Score 结果。 每个插件在每个调度周期调用一次。
保留资源
Reserve
实现了 Reserve 扩展的插件,拥有两个方法,即 Reserve 和 Unreserve, 他们分别支持两个名为 Reserve 和 Unreserve 的信息处理性质的调度阶段。 维护运行时状态的插件(又称 "有状态插件")应该使用这两个阶段,以便在节点上的资源被保留和未保留给特定的 Pod 时得到调度器的通知。
Reserve 阶段发生在调度器实际将一个 Pod 绑定到其指定节点之前。 它的存在是为了防止在调度器等待绑定成功时发生竞争情况。 每个 Reserve 插件的 Reserve 方法可能成功,也可能失败; 如果一个 Reserve 方法调用失败,后面的插件就不会被执行,Reserve 阶段被认为失败。 如果所有插件的 Reserve 方法都成功了,Reserve 阶段就被认为是成功的,剩下的调度周期和绑定周期就会被执行。
如果 Reserve 阶段或后续阶段失败了,则触发 Unreserve 阶段。发生这种情况时,所有 Reserve 插件的 Unreserve 方法将按照 Reserve 方法调用的相反顺序执行。这个阶段的存在是为了清理与保留的 Pod 相关的状态。
这个是调度周期的最后一步。一旦 Pod 处于保留状态,它将在绑定周期结束时触发 Unreserve 插件(失败时)或 PostBind 插件(成功时)。
批准、拒绝、等待
Permit
Permit 插件在每个 Pod 调度周期的最后调用,用于防止或延迟 Pod 的绑定。 一个允许插件可以做以下三件事之一:
- 批准
一旦所有 Permit 插件批准 Pod 后,该 Pod 将被发送以进行绑定。 - 拒绝
如果任何 Permit 插件拒绝 Pod,则该 Pod 将被返回到调度队列。 这将触发 Reserve 插件中的 Unreserve 阶段。 - 等待(带有超时)
如果一个 Permit 插件返回 “等待” 结果,则 Pod 将保持在一个内部的 “等待中” 的 Pod 列表,同时该 Pod 的绑定周期启动时即直接阻塞直到得到批准。 如果超时发生,等待变成拒绝,并且 Pod 将返回调度队列,从而触发 Reserve 插件中的 Unreserve 阶段。
绑定
PreBind
这些插件用于执行 Pod 绑定前所需的所有工作。 例如,一个 PreBind 插件可能需要制备网络卷并且在允许 Pod 运行在该节点之前 将其挂载到目标节点上。
如果任何 PreBind 插件返回错误,则 Pod 将被拒绝并且退回到调度队列中。
Bind
Bind 插件用于将 Pod 绑定到节点上。直到所有的 PreBind 插件都完成,Bind 插件才会被调用。各 Bind 插件按照配置顺序被调用。Bind 插件可以选择是否处理指定的 Pod。 如果某 Bind 插件选择处理某 Pod,剩余的 Bind 插件将被跳过。
PostBind
这是个信息性的扩展点。 PostBind 插件在 Pod 成功绑定后被调用。这是绑定周期的结尾,可用于清理相关的资源。
Unreserve
这是个信息性的扩展点。 如果 Pod 被保留,然后在后面的阶段中被拒绝,则 Unreserve 插件将被通知。 Unreserve 插件应该清楚保留 Pod 的相关状态。
使用此扩展点的插件通常也使用 Reserve。
查看各个节点插件
插件路径pkg/scheduler/framework/plugins/registry.go
func NewInTreeRegistry() runtime.Registry {
fts := plfeature.Features{
EnableDynamicResourceAllocation: feature.DefaultFeatureGate.Enabled(features.DynamicResourceAllocation),
EnableReadWriteOncePod: feature.DefaultFeatureGate.Enabled(features.ReadWriteOncePod),
EnableVolumeCapacityPriority: feature.DefaultFeatureGate.Enabled(features.VolumeCapacityPriority),
EnableMinDomainsInPodTopologySpread: feature.DefaultFeatureGate.Enabled(features.MinDomainsInPodTopologySpread),
EnableNodeInclusionPolicyInPodTopologySpread: feature.DefaultFeatureGate.Enabled(features.NodeInclusionPolicyInPodTopologySpread),
EnableMatchLabelKeysInPodTopologySpread: feature.DefaultFeatureGate.Enabled(features.MatchLabelKeysInPodTopologySpread),
EnablePodSchedulingReadiness: feature.DefaultFeatureGate.Enabled(features.PodSchedulingReadiness),
EnablePodDisruptionConditions: feature.DefaultFeatureGate.Enabled(features.PodDisruptionConditions),
EnableInPlacePodVerticalScaling: feature.DefaultFeatureGate.Enabled(features.InPlacePodVerticalScaling),
EnableSidecarContainers: feature.DefaultFeatureGate.Enabled(features.SidecarContainers),
}
registry := runtime.Registry{
dynamicresources.Name: runtime.FactoryAdapter(fts, dynamicresources.New),
selectorspread.Name: selectorspread.New,
imagelocality.Name: imagelocality.New,
tainttoleration.Name: tainttoleration.New,
nodename.Name: nodename.New,
nodeports.Name: nodeports.New,
nodeaffinity.Name: nodeaffinity.New,
podtopologyspread.Name: runtime.FactoryAdapter(fts, podtopologyspread.New),
nodeunschedulable.Name: nodeunschedulable.New,
noderesources.Name: runtime.FactoryAdapter(fts, noderesources.NewFit),
noderesources.BalancedAllocationName: runtime.FactoryAdapter(fts, noderesources.NewBalancedAllocation),
volumebinding.Name: runtime.FactoryAdapter(fts, volumebinding.New),
volumerestrictions.Name: runtime.FactoryAdapter(fts, volumerestrictions.New),
volumezone.Name: volumezone.New,
nodevolumelimits.CSIName: runtime.FactoryAdapter(fts, nodevolumelimits.NewCSI),
nodevolumelimits.EBSName: runtime.FactoryAdapter(fts, nodevolumelimits.NewEBS),
nodevolumelimits.GCEPDName: runtime.FactoryAdapter(fts, nodevolumelimits.NewGCEPD),
nodevolumelimits.AzureDiskName: runtime.FactoryAdapter(fts, nodevolumelimits.NewAzureDisk),
nodevolumelimits.CinderName: runtime.FactoryAdapter(fts, nodevolumelimits.NewCinder),
interpodaffinity.Name: interpodaffinity.New,
queuesort.Name: queuesort.New,
defaultbinder.Name: defaultbinder.New,
defaultpreemption.Name: runtime.FactoryAdapter(fts, defaultpreemption.New),
schedulinggates.Name: runtime.FactoryAdapter(fts, schedulinggates.New),
}
return registry
}
通过查看pkg/scheduler/framework/interface.go文件内容发现,扩展点都是以接口的形式展现,所以插件只需要完成接口就可以被扩展点引用
// PreFilterPlugin is an interface that must be implemented by "PreFilter" plugins.
// These plugins are called at the beginning of the scheduling cycle.
type PreFilterPlugin interface {
Plugin
// PreFilter is called at the beginning of the scheduling cycle. All PreFilter
// plugins must return success or the pod will be rejected. PreFilter could optionally
// return a PreFilterResult to influence which nodes to evaluate downstream. This is useful
// for cases where it is possible to determine the subset of nodes to process in O(1) time.
// When it returns Skip status, returned PreFilterResult and other fields in status are just ignored,
// and coupled Filter plugin/PreFilterExtensions() will be skipped in this scheduling cycle.
PreFilter(ctx context.Context, state *CycleState, p *v1.Pod) (*PreFilterResult, *Status)
// PreFilterExtensions returns a PreFilterExtensions interface if the plugin implements one,
// or nil if it does not. A Pre-filter plugin can provide extensions to incrementally
// modify its pre-processed info. The framework guarantees that the extensions
// AddPod/RemovePod will only be called after PreFilter, possibly on a cloned
// CycleState, and may call those functions more than once before calling
// Filter again on a specific node.
PreFilterExtensions() PreFilterExtensions
}
// FilterPlugin is an interface for Filter plugins. These plugins are called at the
// filter extension point for filtering out hosts that cannot run a pod.
// This concept used to be called 'predicate' in the original scheduler.
// These plugins should return "Success", "Unschedulable" or "Error" in Status.code.
// However, the scheduler accepts other valid codes as well.
// Anything other than "Success" will lead to exclusion of the given host from
// running the pod.
type FilterPlugin interface {
Plugin
// Filter is called by the scheduling framework.
// All FilterPlugins should return "Success" to declare that
// the given node fits the pod. If Filter doesn't return "Success",
// it will return "Unschedulable", "UnschedulableAndUnresolvable" or "Error".
// For the node being evaluated, Filter plugins should look at the passed
// nodeInfo reference for this particular node's information (e.g., pods
// considered to be running on the node) instead of looking it up in the
// NodeInfoSnapshot because we don't guarantee that they will be the same.
// For example, during preemption, we may pass a copy of the original
// nodeInfo object that has some pods removed from it to evaluate the
// possibility of preempting them to schedule the target pod.
Filter(ctx context.Context, state *CycleState, pod *v1.Pod, nodeInfo *NodeInfo) *Status
}
选择一个插件查看方法pkg/scheduler/framework/plugins/nodename/node_name.go,发现只实现了 Filter 方法与 Name 方法,那么就是 Filter 扩展点接口
type NodeName struct{}
var _ framework.FilterPlugin = &NodeName{}
var _ framework.EnqueueExtensions = &NodeName{}
const (
// Name is the name of the plugin used in the plugin registry and configurations.
Name = names.NodeName
// ErrReason returned when node name doesn't match.
ErrReason = "node(s) didn't match the requested node name"
)
// EventsToRegister returns the possible events that may make a Pod
// failed by this plugin schedulable.
func (pl *NodeName) EventsToRegister() []framework.ClusterEventWithHint {
return []framework.ClusterEventWithHint{
{Event: framework.ClusterEvent{Resource: framework.Node, ActionType: framework.Add | framework.Update}},
}
}
// Name returns name of the plugin. It is used in logs, etc.
func (pl *NodeName) Name() string {
return Name
}
// Filter invoked at the filter extension point.
func (pl *NodeName) Filter(ctx context.Context, _ *framework.CycleState, pod *v1.Pod, nodeInfo *framework.NodeInfo) *framework.Status {
if !Fits(pod, nodeInfo) {
return framework.NewStatus(framework.UnschedulableAndUnresolvable, ErrReason)
}
return nil
}
Scheduler 启动流程
kube-scheduler 的启动文件中就包含一个 main入口函数,cli.Run(command)只是 cobra 框架启动格式,实际上具体任务在app.NewSchedulerCommand()下实现
// cmd/kube-scheduler/scheduler.go
func main() {
// 初始化 Cobra.Command 对象
command := app.NewSchedulerCommand()
// 执行命令
code := cli.Run(command)
os.Exit(code)
}
NewSchedulerCommand函数的目的就是初始化参数,并且把参数传给程序 run 函数
// cmd/kube-scheduler/app/server.go
func NewSchedulerCommand(registryOptions ...Option) *cobra.Command {
// 初始化参数
// Options 相当于项目运行的一个参数,最终 Scheduler 的结构体不是这个
opts := options.NewOptions()
cmd := &cobra.Command{
Use: "kube-scheduler",
Long: `......`,
RunE: func(cmd *cobra.Command, args []string) error {
// runCommand 函数,此处是 Cobra 格式,同时把 opts 参数与 args 参数传给函数内部
return runCommand(cmd, opts, registryOptions...)
},
Args: func(cmd *cobra.Command, args []string) error {
for _, arg := range args {
if len(arg) > 0 {
return fmt.Errorf("%q does not take any arguments, got %q", cmd.CommandPath(), args)
}
}
return nil
},
}
......
return cmd
}
Options生成了Scheduler结构体所需要的配置,包括不限于身份认证、密钥、日志、选举等,最后有一步是把Options的内容传给Scheduler结构体
// cmd/kube-scheduler/app/options/options.go
type Options struct {
// The default values.
ComponentConfig *kubeschedulerconfig.KubeSchedulerConfiguration
SecureServing *apiserveroptions.SecureServingOptionsWithLoopback
Authentication *apiserveroptions.DelegatingAuthenticationOptions
Authorization *apiserveroptions.DelegatingAuthorizationOptions
Metrics *metrics.Options
Logs *logs.Options
Deprecated *DeprecatedOptions
LeaderElection *componentbaseconfig.LeaderElectionConfiguration
// ConfigFile is the location of the scheduler server's configuration file.
ConfigFile string
// WriteConfigTo is the path where the default configuration will be written.
WriteConfigTo string
Master string
// Flags hold the parsed CLI flags.
Flags *cliflag.NamedFlagSets
}
// NewOptions returns default scheduler app options.
func NewOptions() *Options {
o := &Options{
SecureServing: apiserveroptions.NewSecureServingOptions().WithLoopback(),
Authentication: apiserveroptions.NewDelegatingAuthenticationOptions(),
Authorization: apiserveroptions.NewDelegatingAuthorizationOptions(),
Deprecated: &DeprecatedOptions{
PodMaxInUnschedulablePodsDuration: 5 * time.Minute,
},
LeaderElection: &componentbaseconfig.LeaderElectionConfiguration{
LeaderElect: true,
LeaseDuration: metav1.Duration{Duration: 15 * time.Second},
RenewDeadline: metav1.Duration{Duration: 10 * time.Second},
RetryPeriod: metav1.Duration{Duration: 2 * time.Second},
ResourceLock: "leases",
ResourceName: "kube-scheduler",
ResourceNamespace: "kube-system",
},
Metrics: metrics.NewOptions(),
Logs: logs.NewOptions(),
}
o.Authentication.TolerateInClusterLookupFailure = true
o.Authentication.RemoteKubeConfigFileOptional = true
o.Authorization.RemoteKubeConfigFileOptional = true
// Set the PairName but leave certificate directory blank to generate in-memory by default
o.SecureServing.ServerCert.CertDirectory = ""
o.SecureServing.ServerCert.PairName = "kube-scheduler"
o.SecureServing.BindPort = kubeschedulerconfig.DefaultKubeSchedulerPort
o.initFlags()
return o
}
runCommand中最重要的就是Setup与Run函数
// cmd/kube-scheduler/app/server.go
// runCommand runs the scheduler.
func runCommand(cmd *cobra.Command, opts *options.Options, registryOptions ...Option) error {
......
// 安装程序根据命令参数和选项创建完整的配置和调度程序
// 生成完成配置文件,初始化 Scheduler 对象
cc, sched, err := Setup(ctx, opts, registryOptions...)
if err != nil {
return err
}
......
// 根据给定的配置执行 Scheduler 程序
return Run(ctx, cc, sched)
}
在Setup函数中最重要的就是scheduler.New方法,初始化scheduler也是加载调度插件的方法。
// cmd/kube-scheduler/app/server.go
// Setup creates a completed config and a scheduler based on the command args and options
// 可以看到 Setup 函数最终返回的是一个 CompletedConfig 就是完成配置文件,还有一个是 Scheduler 就是调度结构体
func Setup(ctx context.Context, opts *options.Options, outOfTreeRegistryOptions ...Option) (*schedulerserverconfig.CompletedConfig, *scheduler.Scheduler, error) {
......
// 初始化 schedulerappconfig.Config 对象
// opts.Config(ctx) 返回的是 (*schedulerappconfig.Config, error),所以 c 就是已经初始化完成的 schedulerappconfig.Config
c, err := opts.Config(ctx)
if err != nil {
return nil, nil, err
}
// Get the completed config
// 获取完成的所有配置
// 此处相当于再次封装了一下 schedulerappconfig.Config,具体看 cmd/kube-scheduler/app/config/config.go
// schedulerserverconfig 就是 schedulerappconfig 导入包的时候别名
cc := c.Complete()
// 初始化外部树的插件,默认没有
outOfTreeRegistry := make(runtime.Registry)
for _, option := range outOfTreeRegistryOptions {
if err := option(outOfTreeRegistry); err != nil {
return nil, nil, err
}
}
recorderFactory := getRecorderFactory(&cc)
completedProfiles := make([]kubeschedulerconfig.KubeSchedulerProfile, 0)
// Create the scheduler.
// 初始化 Scheduler
// schedulerserverconfig.Config 已经初始化完成了那么就通过配置文件内容初始化 scheduler 结构体。
sched, err := scheduler.New(ctx,
cc.Client,
cc.InformerFactory,
cc.DynInformerFactory,
recorderFactory,
scheduler.WithComponentConfigVersion(cc.ComponentConfig.TypeMeta.APIVersion),
scheduler.WithKubeConfig(cc.KubeConfig),
scheduler.WithProfiles(cc.ComponentConfig.Profiles...),
scheduler.WithPercentageOfNodesToScore(cc.ComponentConfig.PercentageOfNodesToScore),
scheduler.WithFrameworkOutOfTreeRegistry(outOfTreeRegistry),
scheduler.WithPodMaxBackoffSeconds(cc.ComponentConfig.PodMaxBackoffSeconds),
scheduler.WithPodInitialBackoffSeconds(cc.ComponentConfig.PodInitialBackoffSeconds),
scheduler.WithPodMaxInUnschedulablePodsDuration(cc.PodMaxInUnschedulablePodsDuration),
scheduler.WithExtenders(cc.ComponentConfig.Extenders...),
scheduler.WithParallelism(cc.ComponentConfig.Parallelism),
scheduler.WithBuildFrameworkCapturer(func(profile kubeschedulerconfig.KubeSchedulerProfile) {
// Profiles are processed during Framework instantiation to set default plugins and configurations. Capturing them for logging
completedProfiles = append(completedProfiles, profile)
}),
)
......
return &cc, sched, nil
}
在Setup中初始化了schedulerserverconfig.config并完成了初始化scheduler,那么在Run函数中就可以执行scheduler的具体方法。
// cmd/kube-scheduler/app/server.go
// Run executes the scheduler based on the given configuration. It only returns on error or when context is done.
func Run(ctx context.Context, cc *schedulerserverconfig.CompletedConfig, sched *scheduler.Scheduler) error {
......
sched.Run(ctx)
return fmt.Errorf("finished without leader elect")
}
Scheduler New 方法分析
调度器的主要功能就是Watch未调度的 Pod,找到一个合适的 Node 节点,追加到 Pod 结构体中然后回写到 ApiServer
调度器运行最终是调用的Scheduler结构体的Run方法,那么我们先简单看一下结构体存了哪些信息
// pkg/scheduler/scheduler.go
// Scheduler watches for new unscheduled pods. It attempts to find
// nodes that they fit on and writes bindings back to the api server.
type Scheduler struct {
// It is expected that changes made via Cache will be observed
// by NodeLister and Algorithm.
// 预计通过 Cache 所做的更改将被 NodeLister 和算法观察到。
Cache internalcache.Cache
// 扩展器是外部进程影响Kubernetes做出的调度决策的接口,通常是不由Kubernetes直接管理的资源所需要的。
Extenders []framework.Extender
// NextPod should be a function that blocks until the next pod
// is available. We don't use a channel for this, because scheduling
// a pod may take some amount of time and we don't want pods to get
// stale while they sit in a channel.
// 以阻塞的形式获取下一个有效的待调度的Pod。这里不使用channel,主要是因为对一个pod的调度可能需要一些时间
NextPod func() *framework.QueuedPodInfo
// FailureHandler is called upon a scheduling failure.
// 调度失败处理 Handler
FailureHandler FailureHandlerFn
// SchedulePod tries to schedule the given pod to one of the nodes in the node list.
// Return a struct of ScheduleResult with the name of suggested host on success,
// otherwise will return a FitError with reasons.
// 试图将一个Pod调度到其中一个节点上,成功则返回 ScheduleResult, 否则返回带有失败原来的 FitError
SchedulePod func(ctx context.Context, fwk framework.Framework, state *framework.CycleState, pod *v1.Pod) (ScheduleResult, error)
// Close this to shut down the scheduler.
StopEverything <-chan struct{}
// SchedulingQueue holds pods to be scheduled
// 等待被调度的Pod队列,也就是说只有从这个队列里获取的Pod才能被调度
SchedulingQueue internalqueue.SchedulingQueue
// Profiles are the scheduling profiles.
// 调度配置profiles
Profiles profile.Map
client clientset.Interface
// node 快照信息
nodeInfoSnapshot *internalcache.Snapshot
// 节点得分百分比
percentageOfNodesToScore int32
nextStartNodeIndex int
// logger *must* be initialized when creating a Scheduler,
// otherwise logging functions will access a nil sink and
// panic.
logger klog.Logger
// registeredHandlers contains the registrations of all handlers. It's used to check if all handlers have finished syncing before the scheduling cycles start.
registeredHandlers []cache.ResourceEventHandlerRegistration
}
分析了结构体信息后,在Setup函数中详细分析一下Scheduler New 了哪些内容
先看一下Setup中把options值传给了schedulerappconfig.conf,此处通过schedulerserverconfig.conf初始化scheduler
// cmd/kube-scheduler/app/server.go
// Setup creates a completed config and a scheduler based on the command args and options
func Setup(ctx context.Context, opts *options.Options, outOfTreeRegistryOptions ...Option) (*schedulerserverconfig.CompletedConfig, *scheduler.Scheduler, error) {
......
sched, err := scheduler.New(ctx,
cc.Client,
cc.InformerFactory,
cc.DynInformerFactory,
recorderFactory,
scheduler.WithComponentConfigVersion(cc.ComponentConfig.TypeMeta.APIVersion),
scheduler.WithKubeConfig(cc.KubeConfig),
scheduler.WithProfiles(cc.ComponentConfig.Profiles...),
scheduler.WithPercentageOfNodesToScore(cc.ComponentConfig.PercentageOfNodesToScore),
scheduler.WithFrameworkOutOfTreeRegistry(outOfTreeRegistry),
scheduler.WithPodMaxBackoffSeconds(cc.ComponentConfig.PodMaxBackoffSeconds),
scheduler.WithPodInitialBackoffSeconds(cc.ComponentConfig.PodInitialBackoffSeconds),
scheduler.WithPodMaxInUnschedulablePodsDuration(cc.PodMaxInUnschedulablePodsDuration),
scheduler.WithExtenders(cc.ComponentConfig.Extenders...),
scheduler.WithParallelism(cc.ComponentConfig.Parallelism),
scheduler.WithBuildFrameworkCapturer(func(profile kubeschedulerconfig.KubeSchedulerProfile) {
// Profiles are processed during Framework instantiation to set default plugins and configurations. Capturing them for logging
completedProfiles = append(completedProfiles, profile)
}),
)
......
return &cc, sched, nil
}
详细看看New函数初始化的内容
// pkg/scheduler/scheduler.go
// New returns a Scheduler
func New(ctx context.Context,
client clientset.Interface,
informerFactory informers.SharedInformerFactory,
dynInformerFactory dynamicinformer.DynamicSharedInformerFactory,
recorderFactory profile.RecorderFactory,
opts ...Option) (*Scheduler, error) {
logger := klog.FromContext(ctx)
stopEverything := ctx.Done()
// 初始化 options
options := defaultSchedulerOptions
// 此处相当于回调,Option 类型是函数,所以相当于把 options 传给函数执行一下
// 把自定义值传给 schedulerOptions
//scheduler.WithComponentConfigVersion 开始都是 option
for _, opt := range opts {
opt(&options)
}
// 此处出现了一个重要结构 Profile
if options.applyDefaultProfile {
var versionedCfg configv1.KubeSchedulerConfiguration
scheme.Scheme.Default(&versionedCfg)
cfg := schedulerapi.KubeSchedulerConfiguration{}
if err := scheme.Scheme.Convert(&versionedCfg, &cfg, nil); err != nil {
return nil, err
}
// 就是把默认的 Profiles 传给 Options.profiles
// 通过指定 "scheduler name" profile,可以用来控制Pod的调度行为,如何为空则默认使用 "default-scheduler" profile
options.profiles = cfg.Profiles
}
// 注册表注册所有树内插件
// registry 类型是 map[string]PluginFactory,就是前面是名称后面是方法
registry := frameworkplugins.NewInTreeRegistry()
// 注册表中合并树外插件,自定义调度插件开发就是在这合并进来
if err := registry.Merge(options.frameworkOutOfTreeRegistry); err != nil {
return nil, err
}
metrics.Register()
// 此处出现了另一个重要结构 extenders
// Extender 是外部进程影响 Kubernetes 调度决策的接口。这通常是 Kubernetes 不直接管理的资源所需要的
extenders, err := buildExtenders(logger, options.extenders, options.profiles)
if err != nil {
return nil, fmt.Errorf("couldn't build extenders: %w", err)
}
// 获取 pod、list 资源列表
podLister := informerFactory.Core().V1().Pods().Lister()
nodeLister := informerFactory.Core().V1().Nodes().Lister()
snapshot := internalcache.NewEmptySnapshot()
// 集群Event事件
metricsRecorder := metrics.NewMetricsAsyncRecorder(1000, time.Second, stopEverything)
// 重点在这
// 按照profiles配置文件给出framework框架
// profile.NewMap返回的类型是map[string]framework.Framework,就是SchedulerName:Framework,其中 framework 里面结构多是 []PreEnqueuePlugin 这种,所以 map 里一个 profile 对应一个 framework
profiles, err := profile.NewMap(ctx,
// 调度器配置
options.profiles,
// 注册表
registry,
// 事件记录器
recorderFactory,
// componentConfig 版本号
frameworkruntime.WithComponentConfigVersion(options.componentConfigVersion),
// client 客户端
frameworkruntime.WithClientSet(client),
// kubeConfig 配置文件
frameworkruntime.WithKubeConfig(options.kubeConfig),
// SharedInformerFactory
frameworkruntime.WithInformerFactory(informerFactory),
// SharedLister
frameworkruntime.WithSnapshotSharedLister(snapshot),
frameworkruntime.WithCaptureProfile(frameworkruntime.CaptureProfile(options.frameworkCapturer)),
// 设置并行调度数量,默认为16
frameworkruntime.WithParallelism(int(options.parallelism)),
// 外部扩展器
frameworkruntime.WithExtenders(extenders),
// metrics 指标
frameworkruntime.WithMetricsRecorder(metricsRecorder),
)
if err != nil {
return nil, fmt.Errorf("initializing profiles: %v", err)
}
if len(profiles) == 0 {
return nil, errors.New("at least one profile is required")
}
// 预入队插件映射
preEnqueuePluginMap := make(map[string][]framework.PreEnqueuePlugin)
// 每个配置文件的排队提示
queueingHintsPerProfile := make(internalqueue.QueueingHintMapPerProfile)
首先遍历 profiles 获取其对应的已注册好的 PreQueuePlugin 插件,这些插件是在将Pods添加到 activeQ 之前调用。
for profileName, profile := range profiles {
preEnqueuePluginMap[profileName] = profile.PreEnqueuePlugins()
queueingHintsPerProfile[profileName] = buildQueueingHintMap(profile.EnqueueExtensions())
}
// 创建队列
// 将优先级队列初始化为新的调度队列
podQueue := internalqueue.NewSchedulingQueue(
//排队函数
profiles[options.profiles[0].SchedulerName].QueueSortFunc(),
// sharedInformerFactory
informerFactory,
// 设置 pod 的 Initial 阶段的 Backoff 的持续时间
internalqueue.WithPodInitialBackoffDuration(time.Duration(options.podInitialBackoffSeconds)*time.Second),
// 最大backoff持续时间
internalqueue.WithPodMaxBackoffDuration(time.Duration(options.podMaxBackoffSeconds)*time.Second),
// 设置podLister
internalqueue.WithPodLister(podLister),
// 一个 pod 在 unschedulablePods 停留的最长时间
internalqueue.WithPodMaxInUnschedulablePodsDuration(options.podMaxInUnschedulablePodsDuration),
// preEnqueuePluginMap 插件注册
internalqueue.WithPreEnqueuePluginMap(preEnqueuePluginMap),
// 每个带有配置文件的插件注册
internalqueue.WithQueueingHintMapPerProfile(queueingHintsPerProfile),
// 指标
internalqueue.WithPluginMetricsSamplePercent(pluginMetricsSamplePercent),
internalqueue.WithMetricsRecorder(*metricsRecorder),
)
// 把 pod 队列给到每个 framework
for _, fwk := range profiles {
fwk.SetPodNominator(podQueue)
}
// 缓存
schedulerCache := internalcache.New(ctx, durationToExpireAssumedPod)
// Setup cache debugger.
debugger := cachedebugger.New(nodeLister, podLister, schedulerCache, podQueue)
debugger.ListenForSignal(ctx)
sched := &Scheduler{
Cache: schedulerCache,
client: client,
nodeInfoSnapshot: snapshot,
percentageOfNodesToScore: options.percentageOfNodesToScore,
Extenders: extenders,
NextPod: internalqueue.MakeNextPodFunc(logger, podQueue),
StopEverything: stopEverything,
SchedulingQueue: podQueue,
Profiles: profiles,
logger: logger,
}
// 添加默认处理程序此处是重点
sched.applyDefaultHandlers()
// event 处理程序
if err = addAllEventHandlers(sched, informerFactory, dynInformerFactory, unionedGVKs(queueingHintsPerProfile)); err != nil {
return nil, fmt.Errorf("adding event handlers: %w", err)
}
return sched, nil
}
Setup之后就是处理Run函数了
Run 函数中有两个重要部分是sched.SchedulingQueue.Run(logger)与sched.scheduleOne
// pkg/scheduler/scheduler.go
// Run begins watching and scheduling. It starts scheduling and blocked until the context is done.
func (sched *Scheduler) Run(ctx context.Context) {
logger := klog.FromContext(ctx)
// 启用调度器的队列
sched.SchedulingQueue.Run(logger)
// We need to start scheduleOne loop in a dedicated goroutine,
// because scheduleOne function hangs on getting the next item
// from the SchedulingQueue.
// If there are no new pods to schedule, it will be hanging there
// and if done in this goroutine it will be blocking closing
// SchedulingQueue, in effect causing a deadlock on shutdown.
// loop 启动调度程序,loop 是 wait.UntilWithContext 的功能
go wait.UntilWithContext(ctx, sched.scheduleOne, 0)
<-ctx.Done()
sched.SchedulingQueue.Close()
}
队列
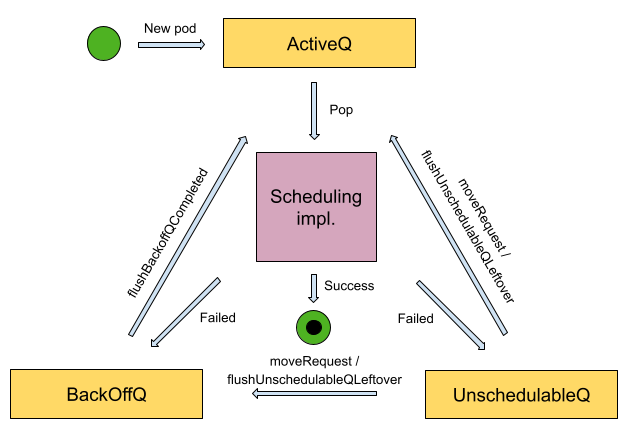
排队机制是调度程序的一个组成部分。它允许调度程序为下一个调度周期选择最合适的 Pod。鉴于 pod 可以指定调度时必须满足的各种条件,例如持久卷的存在、遵守 pod 反亲和性规则或节点污点的容忍度,该机制需要能够推迟调度操作直到集群满足调度成功的所有条件。该机制依赖于三个队列:
- 活动队列(activeQ):用来存放等待调度的 Pod 队列。
- 不可调度队列(unschedulableQ):当 Pod 不能满足被调度的条件的时候就会被加入到这个不可调度的队列中来,等待后续继续进行尝试调度。
- 回退队列(podBackOffQ):如果任务反复执行还是失败,则会按尝试次数增加等待调度时间,降低重试效率,从而避免反复失败浪费调度资源。对于调度失败的 Pod 会优先存储在 backoff 队列中,等待后续进行重试,可以认为就是重试的队列,只是后续再调度的等待时间会越来越长。
以上是官方给出的调度器的三个队列的功能,我们通过源码角度分析一下怎么实现的。
在Setup之后就是执行Run函数,Run函数里执行了调度队列
sched.SchedulingQueue.Run(logger)中的SchedulingQueue是一个接口,先了解一下接口的定义
// pkg/scheduler/internal/queue/scheduling_queue.go
type SchedulingQueue interface {
framework.PodNominator
// 将 pod 添加到活动队列中。仅当添加新 Pod 时才应调用它,因此 Pod 不可能已处于活动/不可调度/退避队列中
Add(logger klog.Logger, pod *v1.Pod) error
// Activate moves the given pods to activeQ iff they're in unschedulablePods or backoffQ.
// The passed-in pods are originally compiled from plugins that want to activate Pods,
// by injecting the pods through a reserved CycleState struct (PodsToActivate).
// 将给定的 pod 移动到 activeQ,前提是它们位于 unschedulablePods 或 backoffQ 中
Activate(logger klog.Logger, pods map[string]*v1.Pod)
// AddUnschedulableIfNotPresent adds an unschedulable pod back to scheduling queue.
// The podSchedulingCycle represents the current scheduling cycle number which can be
// returned by calling SchedulingCycle().
// 将无法调度的 pod 插入队列中,除非它已经在队列中。通常,PriorityQueue 将不可调度的 Pod 放入“unschedulablePods”中。但如果最近有移动请求,则 pod 会被放入“podBackoffQ”中。
AddUnschedulableIfNotPresent(logger klog.Logger, pod *framework.QueuedPodInfo, podSchedulingCycle int64) error
// SchedulingCycle returns the current number of scheduling cycle which is
// cached by scheduling queue. Normally, incrementing this number whenever
// a pod is popped (e.g. called Pop()) is enough.
// 返回当前调度周期
SchedulingCycle() int64
// Pop removes the head of the queue and returns it. It blocks if the
// queue is empty and waits until a new item is added to the queue.
// 弹出
Pop() (*framework.QueuedPodInfo, error)
// 更新
Update(logger klog.Logger, oldPod, newPod *v1.Pod) error
// 删除
Delete(pod *v1.Pod) error
// TODO(sanposhiho): move all PreEnqueueCkeck to Requeue and delete it from this parameter eventually.
// Some PreEnqueueCheck include event filtering logic based on some in-tree plugins
// and it affect badly to other plugins.
// See https://github.com/kubernetes/kubernetes/issues/110175
// 将所有 pod 从 unschedulablePods 移动到 activeQ 或 backoffQ
MoveAllToActiveOrBackoffQueue(logger klog.Logger, event framework.ClusterEvent, oldObj, newObj interface{}, preCheck PreEnqueueCheck)
// 添加绑定的 pod 时会调用AssignedPodAdded。创建此 Pod 可以使具有匹配亲和力术语的挂起 Pod 成为可调度的
AssignedPodAdded(logger klog.Logger, pod *v1.Pod)
// 当绑定的 pod 更新时,会调用 AssignedPodUpdated。标签的更改可能会使具有匹配亲和力术语的待处理 Pod 成为可调度的。
AssignedPodUpdated(logger klog.Logger, oldPod, newPod *v1.Pod)
PendingPods() ([]*v1.Pod, string)
// Close closes the SchedulingQueue so that the goroutine which is
// waiting to pop items can exit gracefully.
Close()
// Run starts the goroutines managing the queue.
Run(logger klog.Logger)
}
由于接口的定义需要被实现,我们看一下在New一个Scheduler,在哪里被实现的
// pkg/scheduler/scheduler.go
// New returns a Scheduler
func New(ctx context.Context,
client clientset.Interface,
informerFactory informers.SharedInformerFactory,
dynInformerFactory dynamicinformer.DynamicSharedInformerFactory,
recorderFactory profile.RecorderFactory,
opts ...Option) (*Scheduler, error) {
......
// NewSchedulingQueue 返回的是一个接口 SchedulingQueue
podQueue := internalqueue.NewSchedulingQueue(
......
)
......
sched := &Scheduler{
......
SchedulingQueue: podQueue,
......
}
sched.applyDefaultHandlers()
......
// 和普通的控制器一样,有个 EventHandler
if err = addAllEventHandlers(sched, informerFactory, dynInformerFactory, unionedGVKs(queueingHintsPerProfile)); err != nil {
return nil, fmt.Errorf("adding event handlers: %w", err)
}
return sched, nil
}
// NewSchedulingQueue 函数返回值是一个接口,但是返回函数 NewPriorityQueue(lessFn, informerFactory, opts...) 却返回的是一个 PriorityQueue 结构体,所以 PriorityQueue 实现了接口的方法
// pkg/scheduler/internal/queue/scheduling_queue.go
// SchedulingQueue 是一个接口,实际上的队列是 NewPriorityQueue 函数返回的结构体实现了接口的方法。
func NewSchedulingQueue(
lessFn framework.LessFunc,
informerFactory informers.SharedInformerFactory,
opts ...Option) SchedulingQueue {
return NewPriorityQueue(lessFn, informerFactory, opts...)
}
查看一下 NewPriorityQueue 返回的结构体类型,里面有三个类型activeQ podBackoffQ unschedulablePods与上图对应。
// pkg/scheduler/internal/queue/scheduling_queue.go
type PriorityQueue struct {
*nominator
stop chan struct{}
clock clock.Clock
// pod initial backoff duration.
// pod 初始 backoff 的时间
podInitialBackoffDuration time.Duration
// pod maximum backoff duration.
// pod 最大 backoff 的时间
podMaxBackoffDuration time.Duration
// the maximum time a pod can stay in the unschedulablePods.
// pod 最大 Unschedulable 的时间
podMaxInUnschedulablePodsDuration time.Duration
cond sync.Cond
// activeQ is heap structure that scheduler actively looks at to find pods to
// schedule. Head of heap is the highest priority pod.
// activeQ 是调度程序主动查看以查找要调度 pod 的堆结构,堆头部是优先级最高的 Pod
activeQ *heap.Heap
// podBackoffQ is a heap ordered by backoff expiry. Pods which have completed backoff
// are popped from this heap before the scheduler looks at activeQ
// backoff 队列
podBackoffQ *heap.Heap
// unschedulablePods holds pods that have been tried and determined unschedulable.
// unschedulableQ 不可调度队列
unschedulablePods *UnschedulablePods
// schedulingCycle represents sequence number of scheduling cycle and is incremented
// when a pod is popped.
// 调度周期的递增序号,当 pop 的时候会增加
schedulingCycle int64
// moveRequestCycle caches the sequence number of scheduling cycle when we
// received a move request. Unschedulable pods in and before this scheduling
// cycle will be put back to activeQueue if we were trying to schedule them
// when we received move request.
moveRequestCycle int64
// preEnqueuePluginMap is keyed with profile name, valued with registered preEnqueue plugins.
// 以配置文件名称为键,通过注册的 preEnqueue 插件进行评估
preEnqueuePluginMap map[string][]framework.PreEnqueuePlugin
// queueingHintMap is keyed with profile name, valued with registered queueing hint functions.
queueingHintMap QueueingHintMapPerProfile
// closed indicates that the queue is closed.
// It is mainly used to let Pop() exit its control loop while waiting for an item.
closed bool
nsLister listersv1.NamespaceLister
metricsRecorder metrics.MetricAsyncRecorder
// pluginMetricsSamplePercent is the percentage of plugin metrics to be sampled.
pluginMetricsSamplePercent int
}
查看具体消息队列初始化,发现主要是生成的一些默认值,生成默认之后,结构体的方法就可以被调用了。
// pkg/scheduler/internal/queue/scheduling_queue.go
// NewPriorityQueue creates a PriorityQueue object.
func NewPriorityQueue(
lessFn framework.LessFunc,
informerFactory informers.SharedInformerFactory,
opts ...Option,
) *PriorityQueue {
options := defaultPriorityQueueOptions
if options.podLister == nil {
options.podLister = informerFactory.Core().V1().Pods().Lister()
}
for _, opt := range opts {
opt(&options)
}
comp := func(podInfo1, podInfo2 interface{}) bool {
pInfo1 := podInfo1.(*framework.QueuedPodInfo)
pInfo2 := podInfo2.(*framework.QueuedPodInfo)
return lessFn(pInfo1, pInfo2)
}
pq := &PriorityQueue{
nominator: newPodNominator(options.podLister),
clock: options.clock,
stop: make(chan struct{}),
podInitialBackoffDuration: options.podInitialBackoffDuration,
podMaxBackoffDuration: options.podMaxBackoffDuration,
podMaxInUnschedulablePodsDuration: options.podMaxInUnschedulablePodsDuration,
// 初始化 activeQ
activeQ: heap.NewWithRecorder(podInfoKeyFunc, comp, metrics.NewActivePodsRecorder()),
// 初始化 unschedulablePods
unschedulablePods: newUnschedulablePods(metrics.NewUnschedulablePodsRecorder(), metrics.NewGatedPodsRecorder()),
moveRequestCycle: -1,
preEnqueuePluginMap: options.preEnqueuePluginMap,
queueingHintMap: options.queueingHintMap,
metricsRecorder: options.metricsRecorder,
pluginMetricsSamplePercent: options.pluginMetricsSamplePercent,
}
pq.cond.L = &pq.lock
// 初始化 BackoffQ
pq.podBackoffQ = heap.NewWithRecorder(podInfoKeyFunc, pq.podsCompareBackoffCompleted, metrics.NewBackoffPodsRecorder())
pq.nsLister = informerFactory.Core().V1().Namespaces().Lister()
return pq
在初始化种发现activeQ backoffQ都是标准的Heap堆,data就是 golang 标准的堆结构体,封装了一下。
// pkg/scheduler/internal/heap/heap.go
// NewWithRecorder wraps an optional metricRecorder to compose a Heap object.
// 包装一个可选的 metricRecorder 来组成一个 Heap 对象
func NewWithRecorder(keyFn KeyFunc, lessFn lessFunc, metricRecorder metrics.MetricRecorder) *Heap {
return &Heap{
data: &data{
items: map[string]*heapItem{},
queue: []string{},
keyFunc: keyFn,
// lessFunc 就是对比函数
lessFunc: lessFn,
},
metricRecorder: metricRecorder,
}
}
// lessFunc is a function that receives two items and returns true if the first
// item should be placed before the second one when the list is sorted.
type lessFunc = func(item1, item2 interface{}) bool
在初始化activeQ是,传入了comp参数,目的是排序,来自profiles[options.profiles[0].SchedulerName].QueueSortFunc(),发现使用的是queueSortPlugins对象queueSortPlugins[0].Less
// pkg/scheduler/framework/runtime/framework.go
// QueueSortFunc 返回用于对调度队列中的 Pod 进行排序的函数
func (f *frameworkImpl) QueueSortFunc() framework.LessFunc {
if f == nil {
// If frameworkImpl is nil, simply keep their order unchanged.
// NOTE: this is primarily for tests.
// 如果 frameworkImpl 为nil,则只需保持其顺序不变
// NOTE: 主要用于测试
return func(_, _ *framework.QueuedPodInfo) bool { return false }
}
// 如果没有 queuesort 插件
if len(f.queueSortPlugins) == 0 {
panic("No QueueSort plugin is registered in the frameworkImpl.")
}
// Only one QueueSort plugin can be enabled.
// 只有一个 QueueSort 插件有效
return f.queueSortPlugins[0].Less
}
最终真正用于优先级队列元素优先级比较的函数是通过 QueueSort 插件来实现的,默认启用的 QueueSort 插件是 PrioritySort
// pkg/scheduler/framework/plugins/queuesort/priority_sort.go
// Less is the function used by the activeQ heap algorithm to sort pods.
// It sorts pods based on their priority. When priorities are equal, it uses
// PodQueueInfo.timestamp.
// Less 是 activeQ 队列用于对 Pod 进行排序的函数。
// 它根据 Pod 的优先级对 Pod 进行排序,
// 当优先级相同时,它使用 PodQueueInfo.timestamp 进行比较
func (pl *PrioritySort) Less(pInfo1, pInfo2 *framework.QueuedPodInfo) bool {
p1 := corev1helpers.PodPriority(pInfo1.Pod)
p2 := corev1helpers.PodPriority(pInfo2.Pod)
return (p1 > p2) || (p1 == p2 && pInfo1.Timestamp.Before(pInfo2.Timestamp))
}
// 获取优先级
// k8s.io/component-helpers/scheduling/corev1/helpers.go
// PodPriority returns priority of the given pod.
func PodPriority(pod *v1.Pod) int32 {
if pod.Spec.Priority != nil {
return *pod.Spec.Priority
}
// When priority of a running pod is nil, it means it was created at a time
// that there was no global default priority class and the priority class
// name of the pod was empty. So, we resolve to the static default priority.
return 0
}
由于上面说过了activeQ与backoffQ都是Heap,初始化都是同一个函数,只不过Less有些区别,所以分析一下unschedulablePods,它返回的是一个结构体,数据存入了podInfoMap字典种,没有Less排序
// pkg/scheduler/internal/queue/scheduling_queue.go
func newUnschedulablePods(unschedulableRecorder, gatedRecorder metrics.MetricRecorder) *UnschedulablePods {
return &UnschedulablePods{
// // podInfoMap 是由 Pod 的全名(podname_namespace)构成的 map key,值是指向 QueuedPodInfo 的指针。
podInfoMap: make(map[string]*framework.QueuedPodInfo),
keyFunc: util.GetPodFullName,
unschedulableRecorder: unschedulableRecorder,
gatedRecorder: gatedRecorder,
}
}
到了此处队列初始化已经完毕,接下来需要分析队列的方法以及用法,回到pkg/scheduler/scheduler.go中,继续查看New方法,addAllEventHandlers 就是跟普通的控制器一样,需要watch到数据,然后放入到队列,再由程序处理时拿到队列里面的key到Cache中查找指定值做处理。
// pkg/scheduler/scheduler.go
// New returns a Scheduler
func New(ctx context.Context,
client clientset.Interface,
informerFactory informers.SharedInformerFactory,
dynInformerFactory dynamicinformer.DynamicSharedInformerFactory,
recorderFactory profile.RecorderFactory,
opts ...Option) (*Scheduler, error) {
......
// 事件处理
if err = addAllEventHandlers(sched, informerFactory, dynInformerFactory, unionedGVKs(queueingHintsPerProfile)); err != nil {
return nil, fmt.Errorf("adding event handlers: %w", err)
}
return sched, nil
}
因为在New中已经把初始化的消息队列给了scheduler结构体,所以此处只需要传递scheduler就行了,在函数中发现它watch了 Pods、Nodes等等一系列数据,我们只简单分析一下。
在AddEventHandler中,AddFunc UpdateFunc DeleteFunc 都是调用的SchedulingQueue接口的方法,在调度器中PriorityQueue实现了该接口,所以只需要理解这个结构体的方法就行了。
// pkg/scheduler/eventhandlers.go
// addAllEventHandlers is a helper function used in tests and in Scheduler
// to add event handlers for various informers.
func addAllEventHandlers(
sched *Scheduler,
informerFactory informers.SharedInformerFactory,
dynInformerFactory dynamicinformer.DynamicSharedInformerFactory,
gvkMap map[framework.GVK]framework.ActionType,
) error {
var (
handlerRegistration cache.ResourceEventHandlerRegistration
err error
handlers []cache.ResourceEventHandlerRegistration
)
// scheduled pod cache
if handlerRegistration, err = informerFactory.Core().V1().Pods().Informer().AddEventHandler(
cache.FilteringResourceEventHandler{
FilterFunc: func(obj interface{}) bool {
switch t := obj.(type) {
case *v1.Pod:
return assignedPod(t)
case cache.DeletedFinalStateUnknown:
if _, ok := t.Obj.(*v1.Pod); ok {
// The carried object may be stale, so we don't use it to check if
// it's assigned or not. Attempting to cleanup anyways.
return true
}
utilruntime.HandleError(fmt.Errorf("unable to convert object %T to *v1.Pod in %T", obj, sched))
return false
default:
utilruntime.HandleError(fmt.Errorf("unable to handle object in %T: %T", sched, obj))
return false
}
},
Handler: cache.ResourceEventHandlerFuncs{
AddFunc: sched.addPodToCache,
UpdateFunc: sched.updatePodInCache,
DeleteFunc: sched.deletePodFromCache,
},
},
); err != nil {
return err
}
handlers = append(handlers, handlerRegistration)
// unscheduled pod queue
if handlerRegistration, err = informerFactory.Core().V1().Pods().Informer().AddEventHandler(
cache.FilteringResourceEventHandler{
FilterFunc: func(obj interface{}) bool {
switch t := obj.(type) {
case *v1.Pod:
return !assignedPod(t) && responsibleForPod(t, sched.Profiles)
case cache.DeletedFinalStateUnknown:
if pod, ok := t.Obj.(*v1.Pod); ok {
// The carried object may be stale, so we don't use it to check if
// it's assigned or not.
return responsibleForPod(pod, sched.Profiles)
}
utilruntime.HandleError(fmt.Errorf("unable to convert object %T to *v1.Pod in %T", obj, sched))
return false
default:
utilruntime.HandleError(fmt.Errorf("unable to handle object in %T: %T", sched, obj))
return false
}
},
Handler: cache.ResourceEventHandlerFuncs{
AddFunc: sched.addPodToSchedulingQueue,
UpdateFunc: sched.updatePodInSchedulingQueue,
DeleteFunc: sched.deletePodFromSchedulingQueue,
},
},
); err != nil {
return err
}
handlers = append(handlers, handlerRegistration)
if handlerRegistration, err = informerFactory.Core().V1().Nodes().Informer().AddEventHandler(
cache.ResourceEventHandlerFuncs{
AddFunc: sched.addNodeToCache,
UpdateFunc: sched.updateNodeInCache,
DeleteFunc: sched.deleteNodeFromCache,
},
); err != nil {
return err
}
handlers = append(handlers, handlerRegistration)
......
sched.registeredHandlers = handlers
return nil
}
当 Pod 有事件变化后,首先回通过 FilterFunc 函数进行过滤,如果 Pod 没有绑定到节点(未调度)并且使用的是指定的调度器才进入下面的 Handler 进行处理,比如当创建 Pod 以后就会有 onAdd 的添加事件,这里调用的就是 sched.addPodToSchedulingQueue 函数
func (sched *Scheduler) addPodToSchedulingQueue(obj interface{}) {
logger := sched.logger
pod := obj.(*v1.Pod)
logger.V(3).Info("Add event for unscheduled pod", "pod", klog.KObj(pod))
if err := sched.SchedulingQueue.Add(logger, pod); err != nil {
utilruntime.HandleError(fmt.Errorf("unable to queue %T: %v", obj, err))
}
}
在sched.SchedulingQueue.Add中会判断 Pod 是不是新的,是的就会添加到activeQ中
// pkg/scheduler/internal/queue/scheduling_queue.go
// Add adds a pod to the active queue. It should be called only when a new pod
// is added so there is no chance the pod is already in active/unschedulable/backoff queues
func (p *PriorityQueue) Add(logger klog.Logger, pod *v1.Pod) error {
p.lock.Lock()
defer p.lock.Unlock()
// 判断 Pod 是不是新的
pInfo := p.newQueuedPodInfo(pod)
gated := pInfo.Gated
// 添加到 activeQ 中
if added, err := p.addToActiveQ(logger, pInfo); !added {
return err
}
// 如果在 unschedulableQ 队列中,则从改队列移除
if p.unschedulablePods.get(pod) != nil {
logger.Error(nil, "Error: pod is already in the unschedulable queue", "pod", klog.KObj(pod))
p.unschedulablePods.delete(pod, gated)
}
// 从 backoff 队列删除
// Delete pod from backoffQ if it is backing off
if err := p.podBackoffQ.Delete(pInfo); err == nil {
logger.Error(nil, "Error: pod is already in the podBackoff queue", "pod", klog.KObj(pod))
}
logger.V(5).Info("Pod moved to an internal scheduling queue", "pod", klog.KObj(pod), "event", PodAdd, "queue", activeQ)
metrics.SchedulerQueueIncomingPods.WithLabelValues("active", PodAdd).Inc()
p.addNominatedPodUnlocked(logger, pInfo.PodInfo, nil)
p.cond.Broadcast()
return nil
}
调度插件
在上图中Scheduling Cycle是有顺序的首先是PreFilter再是Filter这些都是在 Scheduler 的逻辑函数scheduleOne中运行的。
在 Scheduler 的Run函数中分别执行了sched.SchedulingQueue.Run(logger)与sched.scheduleOne
// pkg/scheduler/scheduler.go
// Run begins watching and scheduling. It starts scheduling and blocked until the context is done.
func (sched *Scheduler) Run(ctx context.Context) {
logger := klog.FromContext(ctx)
// 这个是死循环定期把失败队列里的数据拿给 activeQ
sched.SchedulingQueue.Run(logger)
// We need to start scheduleOne loop in a dedicated goroutine,
// because scheduleOne function hangs on getting the next item
// from the SchedulingQueue.
// If there are no new pods to schedule, it will be hanging there
// and if done in this goroutine it will be blocking closing
// SchedulingQueue, in effect causing a deadlock on shutdown.
// 死循环执行插件逻辑
go wait.UntilWithContext(ctx, sched.scheduleOne, 0)
<-ctx.Done()
sched.SchedulingQueue.Close()
}
查看schedulerOne函数逻辑,里面最重要的是schedulingCycle与bindingCycle两个逻辑,分别对应了打分与绑定
// pkg/scheduler/schedule_one.go
func (sched *Scheduler) scheduleOne(ctx context.Context) {
logger := klog.FromContext(ctx)
// 一直弹一个 Pod 出来
podInfo := sched.NextPod()
// pod could be nil when schedulerQueue is closed
if podInfo == nil || podInfo.Pod == nil {
return
}
pod := podInfo.Pod
// 获取调度器插件
fwk, err := sched.frameworkForPod(pod)
if err != nil {
// This shouldn't happen, because we only accept for scheduling the pods
// which specify a scheduler name that matches one of the profiles.
logger.Error(err, "Error occurred")
return
}
if sched.skipPodSchedule(ctx, fwk, pod) {
return
}
logger.V(3).Info("Attempting to schedule pod", "pod", klog.KObj(pod))
// Synchronously attempt to find a fit for the pod.
start := time.Now()
state := framework.NewCycleState()
state.SetRecordPluginMetrics(rand.Intn(100) < pluginMetricsSamplePercent)
// Initialize an empty podsToActivate struct, which will be filled up by plugins or stay empty.
podsToActivate := framework.NewPodsToActivate()
state.Write(framework.PodsToActivateKey, podsToActivate)
schedulingCycleCtx, cancel := context.WithCancel(ctx)
defer cancel()
// 打分逻辑
// 注意这边的返回,一个是返回的选择的 node 节点,一个是 pod 信息,一个是状态
scheduleResult, assumedPodInfo, status := sched.schedulingCycle(schedulingCycleCtx, state, fwk, podInfo, start, podsToActivate)
if !status.IsSuccess() {
sched.FailureHandler(schedulingCycleCtx, fwk, assumedPodInfo, status, scheduleResult.nominatingInfo, start)
return
}
// bind the pod to its host asynchronously (we can do this b/c of the assumption step above).
go func() {
bindingCycleCtx, cancel := context.WithCancel(ctx)
defer cancel()
metrics.Goroutines.WithLabelValues(metrics.Binding).Inc()
defer metrics.Goroutines.WithLabelValues(metrics.Binding).Dec()
// 绑定逻辑
status := sched.bindingCycle(bindingCycleCtx, state, fwk, scheduleResult, assumedPodInfo, start, podsToActivate)
if !status.IsSuccess() {
sched.handleBindingCycleError(bindingCycleCtx, state, fwk, assumedPodInfo, start, scheduleResult, status)
}
}()
}
调度周期
// pkg/scheduler/schedule_one.go
// schedulingCycle tries to schedule a single Pod.
func (sched *Scheduler) schedulingCycle(
ctx context.Context,
state *framework.CycleState,
fwk framework.Framework,
podInfo *framework.QueuedPodInfo,
start time.Time,
podsToActivate *framework.PodsToActivate,
) (ScheduleResult, *framework.QueuedPodInfo, *framework.Status) {
logger := klog.FromContext(ctx)
pod := podInfo.Pod
// 重点来了,SchedulePod 函数在 Scheduler 初始化时初始化的函数,里面包含了上图的 PreFilter,Filter,PreScore,Score,PostScore
scheduleResult, err := sched.SchedulePod(ctx, fwk, state, pod)
// 如果选择不到 Node 节点执行 PostFilter
if err != nil {
if err == ErrNoNodesAvailable {
status := framework.NewStatus(framework.UnschedulableAndUnresolvable).WithError(err)
return ScheduleResult{nominatingInfo: clearNominatedNode}, podInfo, status
}
fitError, ok := err.(*framework.FitError)
if !ok {
logger.Error(err, "Error selecting node for pod", "pod", klog.KObj(pod))
return ScheduleResult{nominatingInfo: clearNominatedNode}, podInfo, framework.AsStatus(err)
}
// SchedulePod() may have failed because the pod would not fit on any host, so we try to
// preempt, with the expectation that the next time the pod is tried for scheduling it
// will fit due to the preemption. It is also possible that a different pod will schedule
// into the resources that were preempted, but this is harmless.
if !fwk.HasPostFilterPlugins() {
logger.V(3).Info("No PostFilter plugins are registered, so no preemption will be performed")
return ScheduleResult{}, podInfo, framework.NewStatus(framework.Unschedulable).WithError(err)
}
// Run PostFilter plugins to attempt to make the pod schedulable in a future scheduling cycle.
result, status := fwk.RunPostFilterPlugins(ctx, state, pod, fitError.Diagnosis.NodeToStatusMap)
msg := status.Message()
fitError.Diagnosis.PostFilterMsg = msg
if status.Code() == framework.Error {
logger.Error(nil, "Status after running PostFilter plugins for pod", "pod", klog.KObj(pod), "status", msg)
} else {
logger.V(5).Info("Status after running PostFilter plugins for pod", "pod", klog.KObj(pod), "status", msg)
}
var nominatingInfo *framework.NominatingInfo
if result != nil {
nominatingInfo = result.NominatingInfo
}
return ScheduleResult{nominatingInfo: nominatingInfo}, podInfo, framework.NewStatus(framework.Unschedulable).WithError(err)
}
metrics.SchedulingAlgorithmLatency.Observe(metrics.SinceInSeconds(start))
// Tell the cache to assume that a pod now is running on a given node, even though it hasn't been bound yet.
// This allows us to keep scheduling without waiting on binding to occur.
assumedPodInfo := podInfo.DeepCopy()
assumedPod := assumedPodInfo.Pod
// assume modifies `assumedPod` by setting NodeName=scheduleResult.SuggestedHost
err = sched.assume(logger, assumedPod, scheduleResult.SuggestedHost)
if err != nil {
// This is most probably result of a BUG in retrying logic.
// We report an error here so that pod scheduling can be retried.
// This relies on the fact that Error will check if the pod has been bound
// to a node and if so will not add it back to the unscheduled pods queue
// (otherwise this would cause an infinite loop).
return ScheduleResult{nominatingInfo: clearNominatedNode}, assumedPodInfo, framework.AsStatus(err)
}
// Run the Reserve method of reserve plugins.
// 运行 Reserve 插件
if sts := fwk.RunReservePluginsReserve(ctx, state, assumedPod, scheduleResult.SuggestedHost); !sts.IsSuccess() {
// trigger un-reserve to clean up state associated with the reserved Pod
fwk.RunReservePluginsUnreserve(ctx, state, assumedPod, scheduleResult.SuggestedHost)
if forgetErr := sched.Cache.ForgetPod(logger, assumedPod); forgetErr != nil {
logger.Error(forgetErr, "Scheduler cache ForgetPod failed")
}
if sts.IsUnschedulable() {
fitErr := &framework.FitError{
NumAllNodes: 1,
Pod: pod,
Diagnosis: framework.Diagnosis{
NodeToStatusMap: framework.NodeToStatusMap{scheduleResult.SuggestedHost: sts},
UnschedulablePlugins: sets.New(sts.FailedPlugin()),
},
}
return ScheduleResult{nominatingInfo: clearNominatedNode}, assumedPodInfo, framework.NewStatus(sts.Code()).WithError(fitErr)
}
return ScheduleResult{nominatingInfo: clearNominatedNode}, assumedPodInfo, sts
}
// Run "permit" plugins.
// 运行 Permit 插件
runPermitStatus := fwk.RunPermitPlugins(ctx, state, assumedPod, scheduleResult.SuggestedHost)
if !runPermitStatus.IsWait() && !runPermitStatus.IsSuccess() {
// trigger un-reserve to clean up state associated with the reserved Pod
fwk.RunReservePluginsUnreserve(ctx, state, assumedPod, scheduleResult.SuggestedHost)
if forgetErr := sched.Cache.ForgetPod(logger, assumedPod); forgetErr != nil {
logger.Error(forgetErr, "Scheduler cache ForgetPod failed")
}
if runPermitStatus.IsUnschedulable() {
fitErr := &framework.FitError{
NumAllNodes: 1,
Pod: pod,
Diagnosis: framework.Diagnosis{
NodeToStatusMap: framework.NodeToStatusMap{scheduleResult.SuggestedHost: runPermitStatus},
UnschedulablePlugins: sets.New(runPermitStatus.FailedPlugin()),
},
}
return ScheduleResult{nominatingInfo: clearNominatedNode}, assumedPodInfo, framework.NewStatus(runPermitStatus.Code()).WithError(fitErr)
}
return ScheduleResult{nominatingInfo: clearNominatedNode}, assumedPodInfo, runPermitStatus
}
// At the end of a successful scheduling cycle, pop and move up Pods if needed.
if len(podsToActivate.Map) != 0 {
sched.SchedulingQueue.Activate(logger, podsToActivate.Map)
// Clear the entries after activation.
podsToActivate.Map = make(map[string]*v1.Pod)
}
return scheduleResult, assumedPodInfo, nil
}
绑定周期
// pkg/scheduler/schedule_one.go
// bindingCycle tries to bind an assumed Pod.
func (sched *Scheduler) bindingCycle(
ctx context.Context,
state *framework.CycleState,
fwk framework.Framework,
scheduleResult ScheduleResult,
assumedPodInfo *framework.QueuedPodInfo,
start time.Time,
podsToActivate *framework.PodsToActivate) *framework.Status {
logger := klog.FromContext(ctx)
assumedPod := assumedPodInfo.Pod
// Run "permit" plugins.
if status := fwk.WaitOnPermit(ctx, assumedPod); !status.IsSuccess() {
return status
}
// Run "prebind" plugins.
if status := fwk.RunPreBindPlugins(ctx, state, assumedPod, scheduleResult.SuggestedHost); !status.IsSuccess() {
return status
}
// Run "bind" plugins.
if status := sched.bind(ctx, fwk, assumedPod, scheduleResult.SuggestedHost, state); !status.IsSuccess() {
return status
}
// Calculating nodeResourceString can be heavy. Avoid it if klog verbosity is below 2.
logger.V(2).Info("Successfully bound pod to node", "pod", klog.KObj(assumedPod), "node", scheduleResult.SuggestedHost, "evaluatedNodes", scheduleResult.EvaluatedNodes, "feasibleNodes", scheduleResult.FeasibleNodes)
metrics.PodScheduled(fwk.ProfileName(), metrics.SinceInSeconds(start))
metrics.PodSchedulingAttempts.Observe(float64(assumedPodInfo.Attempts))
if assumedPodInfo.InitialAttemptTimestamp != nil {
metrics.PodSchedulingDuration.WithLabelValues(getAttemptsLabel(assumedPodInfo)).Observe(metrics.SinceInSeconds(*assumedPodInfo.InitialAttemptTimestamp))
}
// Run "postbind" plugins.
fwk.RunPostBindPlugins(ctx, state, assumedPod, scheduleResult.SuggestedHost)
// At the end of a successful binding cycle, move up Pods if needed.
if len(podsToActivate.Map) != 0 {
sched.SchedulingQueue.Activate(logger, podsToActivate.Map)
// Unlike the logic in schedulingCycle(), we don't bother deleting the entries
// as `podsToActivate.Map` is no longer consumed.
}
return nil
}
自定义调度插件
上节说到要想实现自定义调度器就需要实现framework包下面的接口,接下来就演示一下如何实现的。
创建一个项目,作为主文件夹,创建一个 main 文件作为程序入口
mkdir scheduler-demo
cd scheduler-demo
touch main
创建一个文件夹 pkg 存放插件代码
mkdir pkg
touch pkg/sample.go
初始化项目
go mod init scheduler-demo
插件代码实现
// pkg/sample.go
package pkg
import (
"context"
"fmt"
v1 "k8s.io/api/core/v1"
"k8s.io/apimachinery/pkg/runtime"
"k8s.io/klog/v2"
"k8s.io/kubernetes/pkg/scheduler/framework"
)
// 未使用变量,但是因为类型是接口,所以 sample 需要实现接口才能被作为值传给变量
// 目的不是为了被引用而是检查接口的实现情况
var _ framework.PreFilterPlugin = &Sample{}
var _ framework.FilterPlugin = &Sample{}
var _ framework.ScorePlugin = &Sample{}
// Name 大写为了被引用
const (
Name = "sample-plugin"
)
// 固定格式 handle
type Sample struct {
handle framework.Handle
}
func (s *Sample) Name() string {
return Name
}
// 固定写法,内容可以填充
func (s *Sample) PreFilter(ctx context.Context, state *framework.CycleState, p *v1.Pod) (*framework.PreFilterResult, *framework.Status) {
return nil, nil
}
// PreFilterExtensions returns prefilter extensions, pod add and remove.
func (s *Sample) PreFilterExtensions() framework.PreFilterExtensions {
return s
}
// AddPod from pre-computed data in cycleState.
// no current need for the NetworkOverhead plugin
func (s *Sample) AddPod(ctx context.Context, cycleState *framework.CycleState, podToSchedule *v1.Pod, podToAdd *framework.PodInfo, nodeInfo *framework.NodeInfo) *framework.Status {
return framework.NewStatus(framework.Success, "")
}
// RemovePod from pre-computed data in cycleState.
// no current need for the NetworkOverhead plugin
func (s *Sample) RemovePod(ctx context.Context, cycleState *framework.CycleState, podToSchedule *v1.Pod, podToRemove *framework.PodInfo, nodeInfo *framework.NodeInfo) *framework.Status {
return framework.NewStatus(framework.Success, "")
}
// Filter : evaluate if node can respect maxNetworkCost requirements
// 固定写法
func (s *Sample) Filter(ctx context.Context, cycleState *framework.CycleState, pod *v1.Pod, nodeInfo *framework.NodeInfo) *framework.Status {
return nil
}
// 固定写法,返回的 int64 是打分值,1-100,如果有多个score,最终分数是和, status 是返回状态
func (s *Sample) Score(ctx context.Context, state *framework.CycleState, p *v1.Pod, nodeName string) (int64, *framework.Status) {
nodeInfo, err := s.handle.SnapshotSharedLister().NodeInfos().Get(nodeName)
if err != nil {
return 0, framework.AsStatus(err)
}
klog.V(3).InfoS("success score, this node %s get %d points", nodeName, 100-len(nodeInfo.Pods))
return int64(100 - len(nodeInfo.Pods)), framework.NewStatus(framework.Success, fmt.Sprintf("success score, this node %s get %d points", nodeName, 100-len(nodeInfo.Pods)))
}
func (s *Sample) ScoreExtensions() framework.ScoreExtensions {
return nil
}
func (s *Sample) NormalizeScore(ctx context.Context, state *framework.CycleState, p *v1.Pod, scores framework.NodeScoreList) *framework.Status {
return nil
}
// New 函数,大写为了被引用
func New(obj runtime.Object, handle framework.Handle) (framework.Plugin, error) {
return &Sample{
handle: handle,
}, nil
}
主程序代码
// main.go
package main
import (
"os"
"k8s.io/component-base/cli"
"k8s.io/kubernetes/cmd/kube-scheduler/app"
"scheduler-demo/pkg"
)
func main() {
// 此处用的 app.NewSchedulerCommand 是正儿八经 kubernetes scheduler 的 Command,说白了就是再起一个调度器。
// 这边没有体现配置文件什么的,其实都在 NewSchedulerCommand 里面实现了。
// 主要是 app.WithPlugin(pkg.Name, pkg.New) 这个是导入自定义插件
command := app.NewSchedulerCommand(
app.WithPlugin(pkg.Name, pkg.New))
code := cli.Run(command)
os.Exit(code)
}
注意点
需要注意的是 kubernetes 包是不允许被外部调用的,所以go mod tidy直接下载是下不下来的。
To use Kubernetes code as a library in other applications, see the list of published components. Use of the k8s.io/kubernetes module or k8s.io/kubernetes/... packages as libraries is not supported.
要将 Kubernetes 代码用作其他应用程序中的库,请参阅已发布组件列表。k8s.io/kubernetes不支持将模块或包用作k8s.io/kubernetes/...库。
需要自行配置go.mod文件,主要是配置 replace
module scheduler-demo
go 1.20
require (
github.com/360EntSecGroup-Skylar/excelize v1.4.1
github.com/caoyingjunz/pixiulib v1.0.0
github.com/gin-gonic/gin v1.9.1
github.com/manifoldco/promptui v0.9.0
k8s.io/api v0.28.0
k8s.io/apimachinery v0.28.0
k8s.io/client-go v0.28.0
k8s.io/component-base v0.28.0
k8s.io/klog v1.0.0
k8s.io/klog/v2 v2.100.1
k8s.io/kubernetes v1.28.0
)
require (
github.com/Azure/go-ansiterm v0.0.0-20210617225240-d185dfc1b5a1 // indirect
github.com/NYTimes/gziphandler v1.1.1 // indirect
github.com/antlr/antlr4/runtime/Go/antlr/v4 v4.0.0-20230305170008-8188dc5388df // indirect
github.com/asaskevich/govalidator v0.0.0-20190424111038-f61b66f89f4a // indirect
github.com/beorn7/perks v1.0.1 // indirect
github.com/blang/semver/v4 v4.0.0 // indirect
github.com/bytedance/sonic v1.9.1 // indirect
github.com/cenkalti/backoff/v4 v4.2.1 // indirect
github.com/cespare/xxhash/v2 v2.2.0 // indirect
github.com/chenzhuoyu/base64x v0.0.0-20221115062448-fe3a3abad311 // indirect
github.com/chzyer/readline v0.0.0-20180603132655-2972be24d48e // indirect
github.com/coreos/go-semver v0.3.1 // indirect
github.com/coreos/go-systemd/v22 v22.5.0 // indirect
github.com/davecgh/go-spew v1.1.1 // indirect
github.com/docker/distribution v2.8.2+incompatible // indirect
github.com/emicklei/go-restful/v3 v3.9.0 // indirect
github.com/evanphx/json-patch v5.6.0+incompatible // indirect
github.com/felixge/httpsnoop v1.0.3 // indirect
github.com/fsnotify/fsnotify v1.6.0 // indirect
github.com/gabriel-vasile/mimetype v1.4.2 // indirect
github.com/gin-contrib/sse v0.1.0 // indirect
github.com/go-logr/logr v1.2.4 // indirect
github.com/go-logr/stdr v1.2.2 // indirect
github.com/go-openapi/jsonpointer v0.19.6 // indirect
github.com/go-openapi/jsonreference v0.20.2 // indirect
github.com/go-openapi/swag v0.22.3 // indirect
github.com/go-playground/locales v0.14.1 // indirect
github.com/go-playground/universal-translator v0.18.1 // indirect
github.com/go-playground/validator/v10 v10.14.0 // indirect
github.com/goccy/go-json v0.10.2 // indirect
github.com/gogo/protobuf v1.3.2 // indirect
github.com/golang/groupcache v0.0.0-20210331224755-41bb18bfe9da // indirect
github.com/golang/protobuf v1.5.3 // indirect
github.com/google/cel-go v0.16.0 // indirect
github.com/google/gnostic-models v0.6.8 // indirect
github.com/google/go-cmp v0.5.9 // indirect
github.com/google/gofuzz v1.2.0 // indirect
github.com/google/uuid v1.3.0 // indirect
github.com/grpc-ecosystem/go-grpc-prometheus v1.2.0 // indirect
github.com/grpc-ecosystem/grpc-gateway/v2 v2.7.0 // indirect
github.com/imdario/mergo v0.3.6 // indirect
github.com/inconshreveable/mousetrap v1.1.0 // indirect
github.com/josharian/intern v1.0.0 // indirect
github.com/json-iterator/go v1.1.12 // indirect
github.com/klauspost/cpuid/v2 v2.2.4 // indirect
github.com/leodido/go-urn v1.2.4 // indirect
github.com/mailru/easyjson v0.7.7 // indirect
github.com/mattn/go-isatty v0.0.19 // indirect
github.com/matttproud/golang_protobuf_extensions v1.0.4 // indirect
github.com/moby/sys/mountinfo v0.6.2 // indirect
github.com/moby/term v0.0.0-20221205130635-1aeaba878587 // indirect
github.com/modern-go/concurrent v0.0.0-20180306012644-bacd9c7ef1dd // indirect
github.com/modern-go/reflect2 v1.0.2 // indirect
github.com/mohae/deepcopy v0.0.0-20170929034955-c48cc78d4826 // indirect
github.com/munnerz/goautoneg v0.0.0-20191010083416-a7dc8b61c822 // indirect
github.com/opencontainers/go-digest v1.0.0 // indirect
github.com/opencontainers/selinux v1.10.0 // indirect
github.com/pelletier/go-toml/v2 v2.0.8 // indirect
github.com/pkg/errors v0.9.1 // indirect
github.com/prometheus/client_golang v1.16.0 // indirect
github.com/prometheus/client_model v0.4.0 // indirect
github.com/prometheus/common v0.44.0 // indirect
github.com/prometheus/procfs v0.10.1 // indirect
github.com/spf13/cobra v1.7.0 // indirect
github.com/spf13/pflag v1.0.5 // indirect
github.com/stoewer/go-strcase v1.2.0 // indirect
github.com/twitchyliquid64/golang-asm v0.15.1 // indirect
github.com/ugorji/go/codec v1.2.11 // indirect
go.etcd.io/etcd/api/v3 v3.5.9 // indirect
go.etcd.io/etcd/client/pkg/v3 v3.5.9 // indirect
go.etcd.io/etcd/client/v3 v3.5.9 // indirect
go.opentelemetry.io/contrib/instrumentation/google.golang.org/grpc/otelgrpc v0.35.0 // indirect
go.opentelemetry.io/contrib/instrumentation/net/http/otelhttp v0.35.1 // indirect
go.opentelemetry.io/otel v1.10.0 // indirect
go.opentelemetry.io/otel/exporters/otlp/internal/retry v1.10.0 // indirect
go.opentelemetry.io/otel/exporters/otlp/otlptrace v1.10.0 // indirect
go.opentelemetry.io/otel/exporters/otlp/otlptrace/otlptracegrpc v1.10.0 // indirect
go.opentelemetry.io/otel/metric v0.31.0 // indirect
go.opentelemetry.io/otel/sdk v1.10.0 // indirect
go.opentelemetry.io/otel/trace v1.10.0 // indirect
go.opentelemetry.io/proto/otlp v0.19.0 // indirect
go.uber.org/atomic v1.10.0 // indirect
go.uber.org/multierr v1.11.0 // indirect
go.uber.org/zap v1.19.0 // indirect
golang.org/x/arch v0.3.0 // indirect
golang.org/x/crypto v0.11.0 // indirect
golang.org/x/exp v0.0.0-20220722155223-a9213eeb770e // indirect
golang.org/x/net v0.13.0 // indirect
golang.org/x/oauth2 v0.8.0 // indirect
golang.org/x/sync v0.2.0 // indirect
golang.org/x/sys v0.10.0 // indirect
golang.org/x/term v0.10.0 // indirect
golang.org/x/text v0.11.0 // indirect
golang.org/x/time v0.3.0 // indirect
google.golang.org/appengine v1.6.7 // indirect
google.golang.org/genproto v0.0.0-20230526161137-0005af68ea54 // indirect
google.golang.org/genproto/googleapis/api v0.0.0-20230525234035-dd9d682886f9 // indirect
google.golang.org/genproto/googleapis/rpc v0.0.0-20230525234030-28d5490b6b19 // indirect
google.golang.org/grpc v1.54.0 // indirect
google.golang.org/protobuf v1.30.0 // indirect
gopkg.in/inf.v0 v0.9.1 // indirect
gopkg.in/natefinch/lumberjack.v2 v2.2.1 // indirect
gopkg.in/yaml.v2 v2.4.0 // indirect
gopkg.in/yaml.v3 v3.0.1 // indirect
k8s.io/apiextensions-apiserver v0.28.0 // indirect
k8s.io/apiserver v0.28.0 // indirect
k8s.io/cloud-provider v0.0.0 // indirect
k8s.io/component-helpers v0.28.0 // indirect
k8s.io/controller-manager v0.28.0 // indirect
k8s.io/csi-translation-lib v0.0.0 // indirect
k8s.io/dynamic-resource-allocation v0.0.0 // indirect
k8s.io/kms v0.28.0 // indirect
k8s.io/kube-openapi v0.0.0-20230717233707-2695361300d9 // indirect
k8s.io/kube-scheduler v0.28.0 // indirect
k8s.io/kubelet v0.28.0 // indirect
k8s.io/mount-utils v0.0.0 // indirect
k8s.io/utils v0.0.0-20230406110748-d93618cff8a2 // indirect
sigs.k8s.io/apiserver-network-proxy/konnectivity-client v0.1.2 // indirect
sigs.k8s.io/json v0.0.0-20221116044647-bc3834ca7abd // indirect
sigs.k8s.io/structured-merge-diff/v4 v4.2.3 // indirect
sigs.k8s.io/yaml v1.3.0 // indirect
)
replace (
k8s.io/apiextensions-apiserver => k8s.io/apiextensions-apiserver v0.28.0
k8s.io/apiserver => k8s.io/apiserver v0.28.0
k8s.io/cli-runtime => k8s.io/cli-runtime v0.28.0
k8s.io/cloud-provider => k8s.io/cloud-provider v0.28.0
k8s.io/cluster-bootstrap => k8s.io/cluster-bootstrap v0.28.0
k8s.io/component-base => k8s.io/component-base v0.28.0
k8s.io/component-helpers => k8s.io/component-helpers v0.28.0
k8s.io/controller-manager => k8s.io/controller-manager v0.28.0
k8s.io/cri-api => k8s.io/cri-api v0.28.0
k8s.io/csi-translation-lib => k8s.io/csi-translation-lib v0.28.0
k8s.io/dynamic-resource-allocation => k8s.io/dynamic-resource-allocation v0.28.0
k8s.io/endpointslice => k8s.io/endpointslice v0.28.0
k8s.io/kube-aggregator => k8s.io/kube-aggregator v0.28.0
k8s.io/kube-controller-manager => k8s.io/kube-controller-manager v0.28.0
k8s.io/kube-proxy => k8s.io/kube-proxy v0.28.0
k8s.io/kube-scheduler => k8s.io/kube-scheduler v0.28.0
k8s.io/kubectl => k8s.io/kubectl v0.28.0
k8s.io/kubelet => k8s.io/kubelet v0.28.0
k8s.io/kubernetes => k8s.io/kubernetes v1.28.0
k8s.io/legacy-cloud-providers => k8s.io/legacy-cloud-providers v0.28.0
k8s.io/metrics => k8s.io/metrics v0.28.0
k8s.io/mount-utils => k8s.io/mount-utils v0.28.0
k8s.io/pod-security-admission => k8s.io/pod-security-admission v0.28.0
k8s.io/sample-apiserver => k8s.io/sample-apiserver v0.28.0
)
构建代码创建 dockerfile,制作镜像,因为我的代码是 1.28 的用的 containerd,所以我只能用 nerdctl 制作
FROM golang:alpine
WORKDIR /
COPY sample-scheduler /usr/local/bin
CMD ["sample-scheduler"]
构建,需要注意的是 kubernetes 的镜像都在 k8s.io 命名空间下,镜像也要制作在下面
nerdctl -n k8s.io build -t sample-scheduler:v0.1.5 .
制作完毕可以使用nerdctl查看
nerdctl -n k8s.io images
编写对于 rbac、serviceaccount、configmap、deployment
apiVersion: v1
kind: ServiceAccount
metadata:
name: scheduler-plugins-scheduler
namespace: scheduler-plugins
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: scheduler-plugins-scheduler
rules:
- apiGroups: ["", "events.k8s.io"]
resources: ["events"]
verbs: ["create", "patch", "update"]
- apiGroups: ["coordination.k8s.io"]
resources: ["leases"]
verbs: ["create"]
- apiGroups: ["coordination.k8s.io"]
resourceNames: ["kube-scheduler"]
resources: ["leases"]
verbs: ["get", "update"]
- apiGroups: [""]
resources: ["endpoints"]
verbs: ["create"]
- apiGroups: [""]
resourceNames: ["kube-scheduler"]
resources: ["endpoints"]
verbs: ["get", "update"]
- apiGroups: [""]
resources: ["nodes"]
verbs: ["get", "list", "watch"]
- apiGroups: [""]
resources: ["pods"]
verbs: ["delete", "get", "list", "watch"]
- apiGroups: [""]
resources: ["bindings", "pods/binding"]
verbs: ["create"]
- apiGroups: [""]
resources: ["pods/status"]
verbs: ["patch", "update"]
- apiGroups: [""]
resources: ["replicationcontrollers", "services"]
verbs: ["get", "list", "watch"]
- apiGroups: ["apps", "extensions"]
resources: ["replicasets"]
verbs: ["get", "list", "watch"]
- apiGroups: ["apps"]
resources: ["statefulsets"]
verbs: ["get", "list", "watch"]
- apiGroups: ["policy"]
resources: ["poddisruptionbudgets"]
verbs: ["get", "list", "watch"]
- apiGroups: [""]
resources: ["persistentvolumeclaims", "persistentvolumes"]
verbs: ["get", "list", "watch", "patch", "update"]
- apiGroups: ["authentication.k8s.io"]
resources: ["tokenreviews"]
verbs: ["create"]
- apiGroups: ["authorization.k8s.io"]
resources: ["subjectaccessreviews"]
verbs: ["create"]
- apiGroups: ["storage.k8s.io"]
resources: ["csinodes", "storageclasses"]
verbs: ["get", "list", "watch"]
- apiGroups: ["scheduling.sigs.k8s.io"]
resources: ["podgroups", "elasticquotas"]
verbs: ["get", "list", "watch", "create", "delete", "update", "patch"]
- apiGroups: [""]
resources: ["configmaps"]
verbs: ["get", "list", "watch"]
- apiGroups: ["storage.k8s.io"]
resources: ["csistoragecapacities","csidrivers","csinodes","storageclasses"]
verbs: ["get", "list", "watch"]
- apiGroups: [""]
resources: ["namespaces"]
verbs: ["get", "list", "watch"]
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: scheduler-plugins-scheduler
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: scheduler-plugins-scheduler
subjects:
- kind: ServiceAccount
name: scheduler-plugins-scheduler
namespace: scheduler-plugins
---
apiVersion: v1
kind: ConfigMap
metadata:
name: scheduler-config
namespace: scheduler-plugins
data:
scheduler-config.yaml: |
apiVersion: kubescheduler.config.k8s.io/v1
kind: KubeSchedulerConfiguration
leaderElection:
leaderElect: false
profiles:
- schedulerName: scheduler-plugins-scheduler
plugins:
score:
disabled:
- name: ImageLocality
- name: TaintToleration
- name: NodeAffinity
- name: PodTopologySpread
- name: NodeResourcesFit
- name: NodeResourcesBalancedAllocation
- name: VolumeBinding
enabled:
- name: sample-plugin
preFilter:
enabled:
- name: sample-plugin
filter:
enabled:
- name: sample-plugin
---
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
component: scheduler
name: scheduler-plugins-scheduler
namespace: scheduler-plugins
spec:
selector:
matchLabels:
component: scheduler
replicas: 1
template:
metadata:
labels:
component: scheduler
spec:
serviceAccountName: scheduler-plugins-scheduler
nodeName: kube01
containers:
- command:
- sample-scheduler
- --config=/etc/kubernetes/scheduler-config.yaml
- --v=3
name: sample-scheduler
image: sample-scheduler:v0.1.5
imagePullPolicy: Never
volumeMounts:
- name: scheduler-config
mountPath: /etc/kubernetes
readOnly: true
hostNetwork: false
hostPID: false
volumes:
- name: scheduler-config
configMap:
name: scheduler-config
注意事项
- 需要注意的是每个版本的
rbac可能权限有些问题,因为我写的代码是1.28部署在1.23上导致失败,所以调度器便携的代码需要注意版本这边的rbac - 需要注意
configmap的编写,这边其实就是使用scheduler添加了一个插件,所以自带的调度插件也会被使用,需要根据需求选择禁用还是开启。 deployment部分要开启log等级才可以有更多日志
测试执行
apiVersion: v1
kind: Pod
metadata:
name: test-sc034
namespace: scheduler-plugins
labels:
app: jixingxing
spec:
containers:
- name: nodeselector
image: busybox
command: ["sleep", "36000"]
schedulerName: scheduler-plugins-scheduler
选择了scheduler-plugins-scheduler调度器,执行一下apply
[root@kube01 test]# kubectl apply -f test-pod.yaml
pod/test-sc037 created
查看 scheduler 日志,success score是自定义插件的日志
I0822 03:01:34.887307 1 eventhandlers.go:126] "Add event for unscheduled pod" pod="scheduler-plugins/test-sc037"
I0822 03:01:34.887454 1 schedule_one.go:93] "Attempting to schedule pod" pod="scheduler-plugins/test-sc037"
I0822 03:01:34.887774 1 simple.go:61] "success score, this node %s get %d points" kube01=86
I0822 03:01:34.887785 1 simple.go:61] "success score, this node %s get %d points" kube02=97
I0822 03:01:34.887961 1 default_binder.go:53] "Attempting to bind pod to node" pod="scheduler-plugins/test-sc037" node="kube02"
I0822 03:01:34.894490 1 schedule_one.go:286] "Successfully bound pod to node" pod="scheduler-plugins/test-sc037" node="kube02" evaluatedNodes=2 feasibleNodes=2
I0822 03:01:34.895075 1 eventhandlers.go:197] "Add event for scheduled pod" pod="scheduler-plugins/test-sc037"
I0822 03:01:34.895130 1 eventhandlers.go:171] "Delete event for unscheduled pod" pod="scheduler-plugins/test-sc037"
预测打分
都是逻辑代码,分析不过来。不分析了😁